Wiktionarydiskussion:Projekt/Ord för ord
Tillvägagångssätt
Hur planerar vi att gå tillväga med korrekturläsning? Personligen ogillar jag @LA2s ovilja att använda botar för korrekturläsning, och jag tycker i övrigt att Runebergs gränssnitt för korrekturläsning är mycket omständligt. Jag har korrekturläst en sida där och kommer inte korrekturläsa mer där (och antagligen inte jättemycket här heller).
Hur känner andra? Om det önskas så kan jag bistå med att importera allt hit och fixa det som går att lösa automatiskt (fel kan förekomma, men det gör ändå att korrekturläsning blir mer läsning och mindre korrektur).
- Skriva ut förkortningar
- Göra uppslagsorden fetstilta
//Skal 20 november 2013 kl. 20.32 (CET)
- Gränssnittet är inte så praktiskt, speciellt när var och varannan rad innehåller specialformaterad text då man måste lägga till taggar manuellt. För Svåra ord tankade jag hem allt och redigerade i en ordbehandlare, och då kunde jag lägga till fet och kursiv stil med enkla kortkommandon. Det krävde dock lite scriptande vid sidan om, så det är inte så praktiskt för den oinsatte. Jag är positiv till att fixa formatering och syntaxfel automatiskt med script och redigera här om det görs på ett sådant sätt att materialet kan exporteras tillbaka till Runeberg efter. Fiskjuice (diskussion) 20 november 2013 kl. 20.58 (CET)
- Vi har ju lite olika behov på wikt och Runeberg. Vi behöver korrekt text och uppdelat efter definition, definitioner ska inte brytas över två sidor, vi vill ha förkortningar utskrivna. Där ska det så gott det går återges exakt, inkl. kursiv stil (också inkl. mindre text?).
- Det går förstås att fixa det för både wikt och Runeberg samtidigt: ange förkortningar med <abbr title="eller">l.</abbr> och sidbrytningar med <span class="sidbrytning"/>. Förkortningarna ändras sedan automatiskt till bara "eller" och sidbrytningen tas bort hos oss; hos Runeberg görs sidbrytningen om till en riktig sådan.
- Om det bara är för kortkommandon för fet och kursiv stil så är det ganska lätt att skapa en "finess" för att fixa kortkommandon som Ctrl/Cmd+F och Ctrl/Cmd+K (eller B och I om vi vill). Är det önskvärt?
- @LA2, spelar det någon roll om radbrytningar försvinner inom en definition? //Skal 21 november 2013 kl. 07.37 (CET)
- Jag har prövat att importera 10 sidor hit. Verkar det bra? Den som känner får gärna korrekturläsa här, så exporterar jag det tillbaka till Runeberg igen sedan. Senare, i ett wikifieringssteg får jag fixa förkortningarna. //Skal 21 november 2013 kl. 13.41 (CET)
- Ser bra ut, ska kika lite mer på det i kväll. Synd att vi inte har Visual Editor här för det hade varit praktiskt för ett sånt här ändamål, men passar inte så bra för att redigera i artikelnamnrymden. För Runebergs del hade det varit bra med den inscannade bilden och en WYSIWYG-editor sida vid sida, men för vår del är detta bra. Fiskjuice (diskussion) 21 november 2013 kl. 15.27 (CET)
- Bra tänkt ang. VisualEditor. Jag ska höra om det skulle gå att aktivera det för Wiktionary-namnrymden eller något annat begränsat område här. //Skal 21 november 2013 kl. 15.40 (CET)
- Jag har skrivit en buggrapport om det, men medan vi väntar så är det förstås möjligt att korrekturläsa på Wikipedia, så slipper vi vänta på VisualEditor. Är det en bra idé att pröva på Wikipedia? //Skal 21 november 2013 kl. 16.05 (CET)
- Det går relativt lätt att lägga till formatering i wikitexten (bara att trycka på ' två eller tre gånger). Det är inte så mycket att ändra heller.
- Några saker som kan formateras automatiskt vid import:
re.sub(u'(jfr|se även) ((\d )?+( \d)?)', '\1 \'\'\2\'\'', re.UNICODE): se även 1 apa 1 -> se även 1 apa 1re.sub(u'se ((\d )?+( \d)?)', '\1 \'\'\1\'\'', re.UNICODE): se 1 apa 1 -> se 1 apa 1
- Borde funka men har inte testat.
- Fiskjuice (diskussion) 21 november 2013 kl. 20.25 (CET)
- Jag har lagt in sida 11-20 där jag gör det efter (jfr|se|se även) kursivt. (med
re.sub(r'(jfr|se även|se) ((\d )?+( \d)?)', r"\1 ''\2''", text)) - Hur som helst - korrekturläs gärna 1-10 först, så har jag något att jobba med för export till Runeberg. (Fast jag kommer nog inte jobba med det förrän nästa vecka.)
- Om det finns intresse kan jag lägga upp mitt importera-från-Runeberg-skript här. Säg till i så fall. Och säg till om du kommer på nåt mer som kan fixas automatiskt. //Skal 21 november 2013 kl. 21.05 (CET)
- Enklast om du har scriptet tills vidare, det kan ju dyka upp fler saker som går att automatisera eller göra bättre och då får vi olika versioner. Ta lite i taget tills vidare, jag kan hjälpa till att importera resten sen. Fiskjuice (diskussion) 22 november 2013 kl. 11.30 (CET)
- Jag har lagt in sida 11-20 där jag gör det efter (jfr|se|se även) kursivt. (med
- Några fler saker som kan automatiseras:
- en etta direkt efter uppslagsordet kan göras fet: definition 1 -> definition 1
- till listan 'jfr|se även|se' kan läggas se under och se vidare under
- om det står t.ex.
, daggmask 7,kan det göras kursivt:re.sub(', (+),', r", ''\1'',")
- Fiskjuice (diskussion) 23 november 2013 kl. 21.40 (CET)
- Några fler saker som kan automatiseras:
- Att göra etta efter uppslagsord och lägga till se under och se vidare under verkar bra. Den sista funkar nog också, men i så fall med:
re.sub(r', (+ \d+),', ", ''\1''," ). //Skal 23 november 2013 kl. 21.51 (CET)
- Att göra etta efter uppslagsord och lägga till se under och se vidare under verkar bra. Den sista funkar nog också, men i så fall med:
- Jag har formaterat automatiskt dom sidor som inte hade korrekturlästs.
- Det går sällan att fixa regex helt utan att testa först. Eftersom vi vill att flera ord på rad, ska kunna kursiveras (,bedja 1, begära 1,) så blev det till slut:
sub(', (+ \d+)(?=,)', ", ''\1''"). //Skal 23 november 2013 kl. 22.31 (CET)
- Ja, det är svårt att tänka på alla specialfall i förväg. Hur som helst, tack för att du fixade det. Fiskjuice (diskussion) 23 november 2013 kl. 22.38 (CET)
- De har aktiverat VisualEditor på användarnamnrymden nu, så om vi tror att det blir enklare så, så kan vi flytta korrekturläsningen dit. (Man måste aktivera det i inställningarna.) //Skal 3 december 2013 kl. 15.26 (CET)
- Bra, kan ju testa på några sidor först för att se om det underlättar. Misstänker att det kan bli problem med att få radbrytningarna rätt. Jag har tyvärr inte mycket tid att lägga på detta just nu så vi får se när det blir av. Fiskjuice (diskussion) 3 december 2013 kl. 19.01 (CET)
- Ja, risken är att det blir jobbigt med radbrytningarna. Dom markeras i VisualEditor med ett särskilt tecken: "↵". Du avgör.
- För min del är det ingen stress med projektet. //Skal 3 december 2013 kl. 20.42 (CET)
Lägga till böjningstabeller automatiskt
Jag går händelserna i förväg lite men jag kom att tänka på en metod att lägga till böjningstabeller automatiskt för ett stort antal nya uppslag. Vi har redan uppskattningsvis 30 - 40 tusen uppslag med korrekta böjningstabeller. Dessa kan användas till böjningstabeller för nya ord eftersom ord med samma ändelser ofta har samma böjning (med undantag förstås). T.ex. rökare och skräddare har båda {{sv-subst-n-0|rot=...|are=}}. Sannolikheten att ett nytt ord i -are har samma böjning är alltså stor. Man kan då utgående från existerande uppslag bygga upp en sannolikhetstabell för de 4, 3 och 2 sista bokstäverna i alla existerande ord, och för varje nytt ord försöka först hitta existerande ord med samma fyra sista bokstäver och av dem ta den mest sannolika böjningen, och om inget sådant ord existerar prova de tre sista bokstäverna o.s.v. Detta borde fungera för de flesta utom väldigt korta ord. Fiskjuice (diskussion) 6 december 2013 kl. 21.06 (CET)
- Hmm... det kan gå. Det knepiga är att veta vad man ska placera i en parameter som rot=, men också där kan det känna av om det t.ex. ska vara "ordet, men ta bort x bokstäver på slutet".
- Planerar du att skriva skript för detta?
- Detta kan för övrigt användas till att lägga till böjningstabeller i dom uppslag som saknar också (fast med manuell kontroll). //Skal 6 december 2013 kl. 21.30 (CET)
Tecknet |¯|_|
Vissa definitioner innehåller ett tecken som ser ut som ett liggande S (se t.ex. anlägga på ). Är det något som behöver vara med? Jag har försökt hitta ett motsvarande UNICODE-tecken men det är helt ogoogelbart. Fiskjuice (diskussion) 23 november 2013 kl. 10.55 (CET)
- I bokens anvisningar står det "upplösningstecknet anger lös sammansättning". Det närmaste jag hittade var ₪ (Shekel sign). Fiskjuice (diskussion) 23 november 2013 kl. 16.20 (CET)
- Om du kollar historiken för första sidan så ser du att vi är fler som inte hittar tecknet. Vi är åtminstone fem personer som tittat på det, dig medräknad. Någon föreslog antingen ♮ eller 𝆗 (återställningstecken i musiknotation, eller MUSICAL SYMBOL TURN). "Shekel sign" är också rätt bra och har fördelen att man som icke-israelit inte känner igen det. Ett annat alternativ är ᔓ (CANADIAN SYLLABICS SHO).
- "Upplösningstecknet |¯|_| anger lös sammansättning." Betyder det att sammansättningen inte är helt etablerad?
- @LA2, kan du säga om det är värt att ha med? Vilket tecken ska vi använda när vi exporterar till Runeberg? Tills vidare föreslår jag att vi kör med {{../ut}} så går ingen info förlorad. //Skal 23 november 2013 kl. 18.14 (CET)
- (konfl.) "Lös sammansättning" innebär väl bara att prefixet sitter löst: "uppta <-> ta upp"?
- Jag har sett ett liknande tecken i betydelsen "dessa ord (bokstäver) ska byta plats", och som används i korrektursammanhang. Jag vet inte vad det heter, men det skulle kanske inte vara orimligt att anta att det varit inspirationen för applikationen på löst sammansatta verb. Huruvida detta är en vedertagen beteckning i ordlistor el.dyl. vet jag dock inte heller. (Jfr. http://publications.europa.eu/code/pdf/360300-sv.pdf )
- Men jag tänker att innan vi hittar det i unicode, så är det nog svårt att föra in ens som en egen rubrik? \Mike 23 november 2013 kl. 18.37 (CET)
- Japp, på svenska heter det egentligen "transponaturtecken". Jämför till exempel http://www.sprakbruk.fi/index.php?mid=2&pid=13&aid=3144 (Punkt c.)
Jag vet dock fortfarande inte vad det heter på engelska, eller om det finns i unicode... Letar vidare. \Mike 23 november 2013 kl. 18.57 (CET)I sin ingående granskning av SAOL 13 (Martola 2007) efterlyser Nina Martola en tydligare behandling av partikelverben, framför allt de som är löst sammansatta (säga till, hålla med etc.). Det är inte tillfredsställande, menar hon, att man hittar partikelverb som oftast är löst sammansatta enbart genom en hänvisning (egentligen bara ett s.k. transponaturtecken) under den fast sammansatta varianten. Nästan alla skriver eller säger torka av och nästan ingen använder varianten avtorka, men det är bara avtorka som är upptaget som lemma i SAOL 13.
- Jag tror inte det finns i Unicode och jag blev inspirerad att fixa en bild:
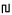 . Jag använde Ord för ord som mall - i rättningssammanhang kanske något annat skulle vara tydligare. //Skal 23 november 2013 kl. 21.14 (CET)
. Jag använde Ord för ord som mall - i rättningssammanhang kanske något annat skulle vara tydligare. //Skal 23 november 2013 kl. 21.14 (CET)
- Jag tror inte det finns i Unicode och jag blev inspirerad att fixa en bild:
- Jag har också letat, men inte hittat detta tecken i Unicode. --LA2 (diskussion) 7 december 2013 kl. 11.25 (CET)
- I den här texten har jag använt tecknet ᆯ som nästan liknar det eftersökta. Var det bra eller dåligt? Ska vi göra det till vår standard? --LA2 (diskussion) 7 december 2013 kl. 21.30 (CET)
- På sidan du länkar på så syns tecknet mycket dåligt för mig (Firefox, Linux) - det ligger på det sista a:et i avtorka. Jag tror att tecknet tolkas lite som en "diakrit" och att webbläsaren försöker kombinera det med andra tecken. //Skal 7 december 2013 kl. 21.42 (CET)
Export till Runeberg.org
Det här är dokumentation av vad som behöver göras för att
Ändringar som görs av wikitext före export och uppladdning till Runeberg.org:
- Automatisk export sker endast om ingen har korrekturläst på Runeberg emellan
- Ändra
'''till<b>och''till<i> - Ändra
== Rubrik ==till<h2> - Ändra
{{../ut}}till ??? - Ändra
{{../tryckfel|felstavat|rättstavat}}till rättstavat och skriv felstavat->rättstavat i redigeringskommentaren (???) - Ta bort
{{../forts}} - Ta bort omfångsanvisningen som anger första och sista ordet på sidan
Angående upplösningstecknet/transponaturtecknet, ska det tas bort, ersättas med annat Unicode-tecken eller ska en bild läggas in? (Och hur lägger man in en bild i så fall?)
Tolkar jag rätt i att man får rätta stavfel om man säger det i en kommentar? Å andra sidan står också "Rätta inga stavfel". //Skal 23 november 2013 kl. 22.54 (CET)
- @Fiskjuice, du la till "Ta bort sidrubriken". Vad betyder det? //Skal 24 november 2013 kl. 20.09 (CET)
- Den översta raden, den som anger första och sista ordet på sidan. Fiskjuice (diskussion) 24 november 2013 kl. 20.21 (CET)
- Är du helt säker på att det ska tas bort? Jag tolkar instruktionerna som att bara förutsägbar information ska tas bort (sidnummer, kapitelinfo, bokinfo, författarinfo). Första och sista ord är bra att ha med. @LA2, du får gärna kommentera här. //Skal 24 november 2013 kl. 21.21 (CET)
- Helt säker är jag inte, det är möjligt att dom reviderat riktlinjerna, men vi hade i alla fall inte med sidrubriker på Svåra ord. Se även en slumpmässig sida i Nordisk familjebok. Fiskjuice (diskussion) 24 november 2013 kl. 21.41 (CET)
- Sidhuvudet (med sidnummer, första och sista ordet, etc.) tas bort i Projekt Runeberg. Sådan information läggs i stället i innehållsförteckningen Articles.lst (motsvarande Index-sidan i Wikisource), som dock inte kan redigeras av allmänheten. Projekt Runeberg är ett projekt med vissa begränsningar. Det får man leva med. --LA2 (diskussion) 7 december 2013 kl. 11.28 (CET)
- Okej, tack för info. @LA2, skulle du kunna ge förslag på vad vi ska göra med upplösningstecknet och bekräfta att det är okej att korrigera tryckfel? //Skal 7 december 2013 kl. 12.59 (CET)