Wiktionary:Grease pit/2015/April
Pashto adjectives
Hello :) I just want to say in Pashto adjectives their is no category of determining gender or number of an adjective the way that there exists with nouns. Pashto adjectives have 3 genders: 1. (Singular) Masculine e.g. سوړ 2. (Singular) Feminine e.g. سړه 3. Neuter e.g. ښه Pashto Adjectives also changes number with with nouns: 1. Plural Masculine e.g. ساړه 2. Plural Feminine e.g. سړې
Is there anything that can be done about this. Thank You PashtoLover (talk) 18:18, 1 April 2015 (UTC)
- I'm not sure what the problem actually is. What do you think should be done? —CodeCat 18:28, 1 April 2015 (UTC)
- I think PashtoLover is pointing out that we currently provide information on the gender and inflected forms of Pashto nouns but apparently not of adjectives (take a look at احمق and ارزان), even though adjectives also inflect based on masculine / feminine gender (sez Wikipedia, citing a book). - -sche (discuss) 18:48, 1 April 2015 (UTC)
Could someone add a namespace check to the categories? We have a Beer Parlour page in Category:English terms with audio links. Renard Migrant (talk) 23:50, 2 April 2015 (UTC)
Double archaics
Hey. If any bot fancies an easy search-and-replace job, there's a few entries here double-tagged as "archaic" "archaic" - for example these ones --Sucio green (talk) 11:41, 3 April 2015 (UTC)
- @Kephir, Buttermilch: needs to clean up the 6,000 entries with this problem. DCDuring TALK 12:15, 3 April 2015 (UTC)
- Ah, so that's what "hyperarchaic" means... Equinox ◑ 13:31, 4 April 2015 (UTC)
- WF is right it's super easy. Renard Migrant (talk) 14:11, 4 April 2015 (UTC)
{{en-archaic second-person singular of}} is so restrictive. I think we should remove the call to {{cx}} from that template rather than remove cx from entries. --Dixtosa (talk) 12:11, 5 April 2015 (UTC)
- It's supposed to be only used for archaic second-person singular forms, why wouldn't it be restrictive? Renard Migrant (talk) 17:17, 5 April 2015 (UTC)
- @Dixtosa, Renard Migrant: What if some, but not all of these are deemed obsolete, literary, rare, or a combination of things? At the very least, the templates needs a means of suppressing the default label. DCDuring TALK 17:36, 5 April 2015 (UTC)
- Why not just use a different template, like
{{form of|literary second-person singular}}? Renard Migrant (talk) 17:37, 5 April 2015 (UTC)- One reason would be that one might hope to use existing knowledge of more general templates rather than ones that were custom to a narrow set of applications. I don't have a problems with a bot coming in a converting them to a more specific template, though I would hope it could be done without leaving 6,000 mistaken entries, ie, the case at hand. DCDuring TALK 23:00, 5 April 2015 (UTC)
- Why not just use a different template, like
- @Dixtosa, Renard Migrant: What if some, but not all of these are deemed obsolete, literary, rare, or a combination of things? At the very least, the templates needs a means of suppressing the default label. DCDuring TALK 17:36, 5 April 2015 (UTC)
Missing forms
Modifying Module:en-headword, I reckon we could find thousands of missing English plurals, adjective and verb forms. --Sucio green (talk) 10:57, 4 April 2015 (UTC)
How to stop AWB following redirects
I would like to use AutoWikiBrowser to replace category directs like Category:Jèrriais auxiliary verbs with {{movecat|Norman auxiliary verbs}}. It's not very hard to do using regexes however, AWB keeps following the direct and tries to edit Category:Norman auxiliary verbs which isn't the category which needs movecat! How do I stop it doing this?
PS see {{movecat/documentation}} for why is a good idea, it categorizes in Category:Category redirects which are not empty which is very useful when trying to track down remaining entries. Renard Migrant (talk) 14:10, 4 April 2015 (UTC)
Can someone look at Template:es-adv? The template automatically qualifies all adverbs as being uncomparable, but some are of course comparable (like rápidamente) but there doesn't seem to be a way of showing that. --Recónditos (talk) 09:41, 5 April 2015 (UTC)
- I can't edit it, but I'd go from
switchtoif. Better to useifwhen only two possibilities. You're right that it claims the default is comparable but it's the opposite; the code for the default is wrong. Renard Migrant (talk) 17:16, 5 April 2015 (UTC)
currently: not comparable
should be:comparable
error: {{#switch:{{{comp|}}}|n|-|=not comparable|#default=comparable}}
--Dixtosa (talk) 18:07, 5 April 2015 (UTC)
{{head}} is linking wrong
It doesn't recognise that : (colon) and ’ (apostrophe), among other punctuation marks, are used as letters in various Amerindian orthographies, and is therefore trying to link the constituents. For example, see the headline of the Han entry tsà’. Can anyone fix the template? It's rather important if we want to even be able to use {{head}} for a large number of languages. —Μετάknowledgediscuss/deeds 02:00, 7 April 2015 (UTC)
- Ideally we shouldn't be using punctuation characters as letters, we should be using their "modifier letter" equivalents (e.g. ʼ instead of ’ or ' and ꞉ instead of :), so tsà’ should be moved to tsàʼ. In the meantime, though, the easiest way to fix it would be to just add
|head=tsà’to force the template to recognize the whole string as the headword. —Aɴɢʀ (talk) 10:59, 7 April 2015 (UTC)- Ideally? Ideally we should use whatever characters people who write in the language in question actually use, not more obscure Unicode offerings (or soft redirects when the two forms are noticeably different but one is considered nonstandard, like using 1 for the palochka). —Μετάknowledgediscuss/deeds 04:22, 8 April 2015 (UTC)
- Hän has about 10 elderly speakers left; I strongly doubt any of them has ever written Hän on a computer. But even for better attested languages your suggestion seems like a very bad idea. We'd have to make entries for things like English don`t and Italian citta' and German muessen and l as a variant spelling of 1 and all sorts of monstrosities people commit when they don't know or care about proper typographic style. The whole reason ʼ exists as a separate Unicode point at all is for cases like this: when a language has something that looks like
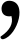 but functions as a letter rather than as a punctuation mark. —Aɴɢʀ (talk) 20:48, 8 April 2015 (UTC)
but functions as a letter rather than as a punctuation mark. —Aɴɢʀ (talk) 20:48, 8 April 2015 (UTC)
- @Angr Firstly, I said "people who write in the language", not speakers; for Hän, that principally means linguists who have described it. More importantly, you seem to be missing the fact that we are descriptivist, not prescriptivist. In fact, since you know German, I urge you to create the entry for meussen, because I checked Google Books and it passes CFI. You may personally think of it as a monstrosity, but people use it, and it therefore qualifies as an entry, presumably as a kind of soft redirect. —Μετάknowledgediscuss/deeds 01:47, 9 April 2015 (UTC)
- Even the linguists who have described it have certainly mostly either written it by hand or by typewriter, and even written by computer, once it's printed out you can't tell the difference between ʼ and ’. That's why the descriptive vs. prescriptive argument is a red herring: as far as human beings are concerned there's no difference between tsà’ and tsàʼ. Only the software knows the difference, and there's nothing "prescriptivist" about using the character the software will treat correctly. We really shouldn't be using the curly apostrophe ’ in entries at all, because we've decided to use the typewriter apostrophe ' for the punctuation mark (e.g. don't), and the modifier letter ʼ should be used in any instance, in any language, where it functions as a letter. The curly apostrophe should only be used in hard redirects like don’t→don't (and, in theory, ajaa’→ajaaʼ though I don't know if we have any such redirects in practice). —Aɴɢʀ (talk) 20:26, 9 April 2015 (UTC)
- @Angr Firstly, I said "people who write in the language", not speakers; for Hän, that principally means linguists who have described it. More importantly, you seem to be missing the fact that we are descriptivist, not prescriptivist. In fact, since you know German, I urge you to create the entry for meussen, because I checked Google Books and it passes CFI. You may personally think of it as a monstrosity, but people use it, and it therefore qualifies as an entry, presumably as a kind of soft redirect. —Μετάknowledgediscuss/deeds 01:47, 9 April 2015 (UTC)
- Hän has about 10 elderly speakers left; I strongly doubt any of them has ever written Hän on a computer. But even for better attested languages your suggestion seems like a very bad idea. We'd have to make entries for things like English don`t and Italian citta' and German muessen and l as a variant spelling of 1 and all sorts of monstrosities people commit when they don't know or care about proper typographic style. The whole reason ʼ exists as a separate Unicode point at all is for cases like this: when a language has something that looks like
- Ideally? Ideally we should use whatever characters people who write in the language in question actually use, not more obscure Unicode offerings (or soft redirects when the two forms are noticeably different but one is considered nonstandard, like using 1 for the palochka). —Μετάknowledgediscuss/deeds 04:22, 8 April 2015 (UTC)
- I agree with Angr that the "descriptive vs prescriptive" argument is largely misplaced. If the documents we are citing words from are printed, we can't tell (unless we have the electronic copies they were printed from) whether they use the punctuation codepoint or the letter codepoint, and we should assume they used the codepoint the software treats correctly. If the documents are typewritten or handwritten, no codepoint was used; it's up to us to decide which one best represents the type-/handwritten letter, and we should use the codepoint the software treats correctly. Only if we are dealing with durably archived electronic media that unambiguously use the punctuation codepoints should we have entries to cover that, and even then, it may be sufficient for those entries to be hard or soft redirects: compare Mʳ and cafe' (see Talk:cafe'). Muessen is an entirely different kind of thing and should have an entry using Template:de-umlautless spelling of like fuer. Don`t could, I hope, be handled by whatever auto-redirect gadget handles long s. - -sche (discuss) 21:00, 9 April 2015 (UTC)
Proper categories for borrowed English first names in Chinese
Please suggest/fix categorisation for entries like 阿道夫 (Ādàofū) (Adolph, Adolf) and 艾麗絲/艾丽丝 (Àilìsī) (Alice). Category:zh:English female given names has an error. There's a bunch of proper noun entries in need of conversion to the new Chinese format, which are all surnames or first names here: Category:Mandarin proper nouns in simplified script. --Anatoli T. (обсудить/вклад) 01:42, 8 April 2015 (UTC)
- @Chuck Entz. Thanks! --Anatoli T. (обсудить/вклад) 02:20, 8 April 2015 (UTC)
- You're welcome. The problem was that name categories aren't topical categories, so you can't have "zh:". I've created all the categories and parent categories needed for the two entries. I think you can figure out the rest for other languages. The parent categories use
{{poscatboiler}}, but "derived from" name categories don't have a template, that I know of, so I just put:- {{catfix|zh}}
- ]
- ]
- {{catfix|zh}}
- You're welcome. The problem was that name categories aren't topical categories, so you can't have "zh:". I've created all the categories and parent categories needed for the two entries. I think you can figure out the rest for other languages. The parent categories use
- and
- {{catfix|zh}}
- ]
- ]
- {{catfix|zh}}
- When creating a parallel category for another language, just change the language name, and you've got it. Chuck Entz (talk) 02:35, 8 April 2015 (UTC)
- Thanks again. --Anatoli T. (обсудить/вклад) 02:53, 8 April 2015 (UTC)
- When creating a parallel category for another language, just change the language name, and you've got it. Chuck Entz (talk) 02:35, 8 April 2015 (UTC)
Rukhabot and interwikis
Rukhabot hasn't worked for nearly three months and User:Ruakh seems out of reach. What's happening with interwikis? Any other bots? --Anatoli T. (обсудить/вклад) 05:55, 8 April 2015 (UTC)
- Sorry about that. It's running now.
- Are there any more-active Wiktionarians who know (and like) Perl and would be interested in taking over the bot?
- —RuakhTALK 15:29, 9 April 2015 (UTC)
- I don't have experience running a bot, but know (and don't mind) Perl. Jberkel (talk) 19:34, 9 April 2015 (UTC)
- @Ruakh Thank you and welcome back. :)--Anatoli T. (обсудить/вклад) 20:55, 9 April 2015 (UTC)
- I don't have experience running a bot, but know (and don't mind) Perl. Jberkel (talk) 19:34, 9 April 2015 (UTC)
Why don't we have the wikidata support?Dixtosa (talk) 20:15, 11 April 2015 (UTC)
- This question has come up many times: the short answer- interwiki politics. Wikidata wants to do what they see as a comprehensive solution rather than the obvious, straightforward solution that we would prefer. There's also some nitpicking about different apostrophes used by different wiktionaries, and that sort of thing. Chuck Entz (talk) 20:23, 11 April 2015 (UTC)
- I do not understand. How can Wikipedia be more structured than us? Actually, the opposite is true: Wikipedia is looser, more general, for example an article in X wiki can be a section on Y wiki;
- There is one concept -> one entry in Wikidata; One word -> one entry in Wikidata.
- The only situation when Wikidata will not be of any use is if X and Y wiktionaries have different interwikis. Does this happen?--Dixtosa (talk) 20:59, 11 April 2015 (UTC)
- Just in case anyone's interested. phabricatorT987--Dixtosa (talk) 13:47, 28 May 2015 (UTC)
Well, removing wikimedia's one of the ids (talking about p-cactions) is really not a clever idea. Some userscripts depend on it.
Also, the id ca-watch is not present if the current page is watchlisted.
So, please, change it to
jQuery(function( $ ) {
var links = jQuery("#p-cactions li").remove();
links.insertBefore("#ca-watch").find("a").wrap("<span>");
links.insertBefore("#ca-unwatch").find("a").wrap("<span>");
});
--Dixtosa (talk) 20:08, 11 April 2015 (UTC)
- Seriously.--Dixtosa (talk) 13:48, 28 May 2015 (UTC)
AutoFormat
Is nobody willing to run an auto-format bot? Category: Requests for autoformat is running into the tens of thousands now. Renard Migrant (talk) 21:16, 11 April 2015 (UTC)
Template:obsolete spelling of
{{obsolete spelling of}} does not provide automatic categorization, i.e. Category:English obsolete terms or Category:English obsolete forms. @-sche: pointed out that using {{term-context|obsolete|lang=en}}, since the term is obsolete, with {{obsolete spelling of}} produces visual double-labelling
in the entry. —BoBoMisiu (talk) 16:27, 15 April 2015 (UTC)
- It does automatically categorize in Category:English obsolete forms (or the corresponding other-language categories) if people remember to set lang=. (Otherwise, it categorizes into the hidden cleanup category Category:Language code missing/form of.) - -sche (discuss) 17:49, 15 April 2015 (UTC)
- @-sche: TVM —BoBoMisiu (talk) 19:15, 15 April 2015 (UTC)
Synonym of
The template {{synonym of}} complains if I omit or misspell the lang= parameter.
But if I spell it correctly it ignores it.
Is this deliberate? SemperBlotto (talk) 15:18, 16 April 2015 (UTC)
- No it does not ignore it. It creates a proper link (e.g. #Italian) using the langcode. Dixtosa (talk) 16:17, 16 April 2015 (UTC)
- OK. I had not noticed that. SemperBlotto (talk) 16:24, 16 April 2015 (UTC)
For some reason, I can't edit ad though I can edit the larger a. I'm trying to correct the fault header in Old French 'Preposition' for the verb form of avoir, but I can't do it. Renard Migrant (talk) 18:17, 18 April 2015 (UTC)
- Probably an ad blocker. Someone else asked this recently. —CodeCat 18:31, 18 April 2015 (UTC)
- Yes, that happened to me too until I went to ad, then clicked on the AdBlockerPlus icon in my menu bar and selected "Disable on this page only". —Aɴɢʀ (talk) 19:25, 18 April 2015 (UTC)
- Yes that's done it. Very odd though! Renard Migrant (talk) 20:20, 18 April 2015 (UTC)
- It's kind of amusing, if you think about it. The adblocker doesn't know the difference between an ad and a mention of the word ad. —Aɴɢʀ (talk) 21:05, 18 April 2015 (UTC)
- Yes. Maybe they should change the name to "Ad"BlockerPlus... Chuck Entz (talk) 21:21, 18 April 2015 (UTC)
- I posted this as an issue on an adblockplus.org/forum/.... —BoBoMisiu (talk) 16:06, 24 April 2015 (UTC)
- A stop gap measure is to add this custom filter
wiktionary.org#@#.page-ad(see here), I think it will get added to the affecting filter list eventually. —BoBoMisiu (talk) 20:04, 24 April 2015 (UTC)
- Yes. Maybe they should change the name to "Ad"BlockerPlus... Chuck Entz (talk) 21:21, 18 April 2015 (UTC)
- It's kind of amusing, if you think about it. The adblocker doesn't know the difference between an ad and a mention of the word ad. —Aɴɢʀ (talk) 21:05, 18 April 2015 (UTC)
- Yes that's done it. Very odd though! Renard Migrant (talk) 20:20, 18 April 2015 (UTC)
- Yes, that happened to me too until I went to ad, then clicked on the AdBlockerPlus icon in my menu bar and selected "Disable on this page only". —Aɴɢʀ (talk) 19:25, 18 April 2015 (UTC)
Could template {{quote-book}} be made to have a line and a lines parameter? Not all texts are in page form, such as epic poems. Also line and lines need to be separate to avoid things like lines 21 and line 21-24, which are both wrong. Renard Migrant (talk) 16:42, 19 April 2015 (UTC)
- User:Internoob/Sandbox is Template:quote-book/source with line= and lines= parameters. Look good? —Internoob 23:15, 30 April 2015 (UTC)
- @Renard Migrant: This shows how User:Internoob/Sandbox works. —Internoob 17:02, 6 May 2015 (UTC)
- This parameter is a useful feature. I hope it will be added to all the templates in the quote- family – poems and such are found everywhere. —BoBoMisiu (talk) 13:42, 8 May 2015 (UTC)
List entries from a category and all its subcats
Today I needed some lists of male and female given names. However, Category:English male given names is split into subcategories (from Hebrew, from Arabic, etc.) and it does not seem possible to view all names from all of those categories in a single list. That's a pity. The same applies to e.g. animals, where they are split into subcats by mammal, reptile, and so on. I can imagine users wanting complete lists of things and sub-things, so we should think about somehow implementing a mechanism to do this. Equinox ◑ 10:05, 23 April 2015 (UTC)
- Good idea. I hope it can be done in real time for all categories that have subcategories, but we could do dump-processing to generate selected lists of that kind. DCDuring TALK 13:18, 23 April 2015 (UTC)
Abbreviation in Russian
It seems that there's an issue in the Russian abbreviation entries. It doesn't have its own headword-line template. See also Talk:прил.. --KoreanQuoter (talk) 11:36, 23 April 2015 (UTC)
- "Abbreviation" is no longer considered a valid part of speech. If, as in this case, the term abbreviated is a noun, then the POS should be ===Noun===, not ===Abbreviation===. This is true for all languages, not just Russian. —Aɴɢʀ (talk) 11:49, 23 April 2015 (UTC)
- This might be late, but really thank you for this piece of info. --KoreanQuoter (talk) 11:47, 25 April 2015 (UTC)
Serious help needed with this template
- Discussion moved from Wiktionary:Information desk/2015/April.
I am currently working on Pashto conjugations, declensions and adding word + categories. Making templates was easy for me until this:
https://en.wiktionary.orghttps://dictious.com/en/Template:ps-conj-simp-irregular-w/o-peculiar3rdperson
I entered the code normally but somehow it is not appearing correctly.
Can someone please help
Adjutor101 (talk) 16:28, 23 April 2015 (UTC)
Solved by Dixtosa Adjutor101 (talk) 16:40, 23 April 2015 (UTC)
Vowel lengthening doesn't work in ru-IPA?
Based on гении, the IPA of this word appears to have "ɪɪ", but I think it should be like "ɪː". I know that gemination (gem=y) is for consonants and that's it. --KoreanQuoter (talk) 11:53, 25 April 2015 (UTC)
- I prefer . You can think of double vowels in Russian both ways - long or duplicated. To my ear, there are no long vowels in Russian, just their duplications. I also pronounce коопера́ция (kooperácija) as , not but "ː" is commonly used in such cases. To be honest, I don't know why. --Anatoli T. (обсудить/вклад) 14:13, 25 April 2015 (UTC)
- That's an interesting way of seeing this. I think it's because Russian doesn't lengthen its vowels. I still prefer using because might give an impression like , and this might be because my first language is Korean. --KoreanQuoter (talk) 14:47, 25 April 2015 (UTC)
- There's really a very simple test for this. Is it two syllables or one? —CodeCat 15:07, 25 April 2015 (UTC)
- I think it's two syllables, although there may not be a /ʔ/ sound between them or just a very slight one. Note that stressed double vowels get the second vowel stressed, e.g. Авраа́м IPA(key): . There's no difference in pronunciation of "по оши́бке" ("in error") or "коали́ция" - as . --Anatoli T. (обсудить/вклад) 15:21, 25 April 2015 (UTC)
- Perhaps is the only unstressed near-closed vowel that can be placed together twice like . I never heard of in Russian, unless if it's in a rare loanword. --KoreanQuoter (talk) 02:54, 26 April 2015 (UTC)
- The same will happen with two "уу" in a row, e.g. "Суунду́к", a small river in Russia (yes, it's a borrowing): If they are on a stressed syllable, then they would be but I don't remember such an example. --Anatoli T. (обсудить/вклад) 02:19, 27 April 2015 (UTC)
- But now, I agree with you: there are no long vowels in Russian, just duplication. --KoreanQuoter (talk) 10:35, 27 April 2015 (UTC)
- The same will happen with two "уу" in a row, e.g. "Суунду́к", a small river in Russia (yes, it's a borrowing): If they are on a stressed syllable, then they would be but I don't remember such an example. --Anatoli T. (обсудить/вклад) 02:19, 27 April 2015 (UTC)
- Perhaps is the only unstressed near-closed vowel that can be placed together twice like . I never heard of in Russian, unless if it's in a rare loanword. --KoreanQuoter (talk) 02:54, 26 April 2015 (UTC)
- I think it's two syllables, although there may not be a /ʔ/ sound between them or just a very slight one. Note that stressed double vowels get the second vowel stressed, e.g. Авраа́м IPA(key): . There's no difference in pronunciation of "по оши́бке" ("in error") or "коали́ция" - as . --Anatoli T. (обсудить/вклад) 15:21, 25 April 2015 (UTC)
- There's really a very simple test for this. Is it two syllables or one? —CodeCat 15:07, 25 April 2015 (UTC)
- That's an interesting way of seeing this. I think it's because Russian doesn't lengthen its vowels. I still prefer using because might give an impression like , and this might be because my first language is Korean. --KoreanQuoter (talk) 14:47, 25 April 2015 (UTC)
How should templates handle parameters in a sequence?
We have quite a few templates that have a parameter that is really an infinitely long set of parameters. For example, {{head}} has head=, head2=, head3= and so on, and also g=, g2=, g3= etc. Thanks to Lua, there really is no limit to how many we can specify. But it's possible that there are "holes" in the series, like {{head|...|g=m|g3=f}} or {{head|...|head2=foo}}. It's not clear how templates should handle these cases, and different templates have different approaches. So I am wondering what we should do here.
The simplest approach, which most templates use currently, is to start at number 1 and advance until you come upon an empty value and stop there. This would mean that {{head|...|g=m|g3=f}} would be equivalent to {{head|...|g=m}}; the g3= parameter would be ignored because g2= is missing. A possible modification could be to include parameters that are specified but left empty. Then {{head|...|g=m|g3=f}} would still read only g= but {{head|...|g=m|g2=|g3=f}} would read all three. Even so, it's still not ideal.
A more advanced approach would be to go through the list of all the provided arguments, and make a list of all g*= parameters first, then sort them. Then read the parameters in the sorted order. This method will read {{head|...|g=m|g3=f}} correctly. The downside is that it's slower, because you have to go through all the parameters first and compile a list, and sorting takes a bit of time too.
It could be argued that skipping a number is an error, so the template shouldn't make any effort to correct it. This is true, but it's highly desirable to be able to specify xx3= while leaving xx2= empty, especially when it comes to templates that directly pass arguments to modules or other templates. So how should this be done? Maybe someone else knows a more effective way to do it? —CodeCat 16:38, 1 May 2015 (UTC)
- You cant sort g* because you might get g1 g10 g11 .. g2. If splitting all given parameters by name and number is OK then this is probably a decent possibility: (pseudocode)
for k, v in parentargs
args = v
name, num = split k
num--
while num != 0
if args == nil:
args = "<this is skipped>"
else: break
num--
- The result is that all g*'s that are between non-nil g's wil be filled with "<this is skipped>".
- It might seem a horrible O(N^2) algorithm, but it is not. It is a linear solution. Even more specifically, every args will be accessed only twice (one read one write at most).
- But I still doubt this will be any better than old-school while loop with the upper bound being inefficiently-looking number like 50 xD. --Dixtosa (talk) 17:36, 1 May 2015 (UTC)
- With your solution, you'd still have to have another pass to remove all elements that read "this is skipped" afterwards. —CodeCat 17:45, 1 May 2015 (UTC)