Wiktionary:Grease pit/2014/October
Can someone please fix some small problems with the module, please? The language name uses an old way and gives module errors. Ideally, it would be great if it could work for other languages as well, e.g. {{zh-new}}. User:Ruakh is no longer supporting it, as he said. --Anatoli T. (обсудить/вклад) 03:09, 1 October 2014 (UTC)
I'm going to try this change: From:
wikitext += '=={{subst:#invoke:languages/templates|lookup|' + tbotData.lang + '|names}}==\n\n';
To:
wikitext += '=={{subst:#invoke:languages/templates|getByCode|' + tbotData.lang + '|getCanonicalName}}==\n\n';
--Anatoli T. (обсудить/вклад) 03:17, 1 October 2014 (UTC)
- Rolled back. It didn't work. The links are no longer green. --Anatoli T. (обсудить/вклад) 03:23, 1 October 2014 (UTC)
- Fixed. The reason it didn't work is that you tried to add some comments like this
' comment, while JavaScript uses comments like this// commentor like this/* comment */. The apostrophe is used for strings, not comments. --WikiTiki89 09:06, 1 October 2014 (UTC)
- Fixed. The reason it didn't work is that you tried to add some comments like this
- Thanks for the fix! I have just tested it on табуляция. --Anatoli T. (обсудить/вклад) 22:56, 1 October 2014 (UTC)
Can you export format_headword, format_transliteration, format_genders, format_inflections? Or let me do it myself, or something
I would like to fix things so that Arabic headwords automatically have vowels filled in based on the transliteration. The reason for this is that tons of Arabic words (nouns, adjectives) currently have a transliteration that specifies the vowels, but no headword with such vowels. I've already written the code to actually fill in the vowels, and I already fill in the vowels in plurals (using {{ar-linkify-bold}}).
Perhaps the cleanest solution that requires the least code duplication would be to modify Module:headword itself (and probably also Module:links to do the same trick in links, although it's less common there to have a transliteration). However, I don't have permission to do this as I'm not an admin, and this might be controversial as it would introduce language-specific code into what's currently largely language-agnostic. An alternative is for me to create my own version of {{head}}; to do this and avoid so much code duplication, I would need the above functions exported.
Benwing (talk) 03:42, 3 October 2014 (UTC)
- Could this not be achieved by editing the pages themselves, so that the linked term includes the vowels? —CodeCat 12:28, 3 October 2014 (UTC)
- The point of doing this is to avoid having to manually edit all the pages.
- I oppose this. What you should do instead is run a bot to add the vowels based on the transliteration. --WikiTiki89 14:43, 3 October 2014 (UTC)
- I don't have any permissions to run any bots or any experience writing them. Can you do things like get all the pages in a particular category, or all the pages that use a particular template? Benwing (talk) 17:42, 4 October 2014 (UTC)
- I would definitely recommend learning how to run a bot. It can make tedious tasks a lot easier. I use Python with pywikibot and mwparserfromhell. It allows all those things and more. —CodeCat 17:57, 4 October 2014 (UTC)
- Or you could request someone else to run a bot. The decision should be based on what has the best end result, not on what you are more skilled at doing. --WikiTiki89 21:04, 6 October 2014 (UTC)
- I would definitely recommend learning how to run a bot. It can make tedious tasks a lot easier. I use Python with pywikibot and mwparserfromhell. It allows all those things and more. —CodeCat 17:57, 4 October 2014 (UTC)
- I don't have any permissions to run any bots or any experience writing them. Can you do things like get all the pages in a particular category, or all the pages that use a particular template? Benwing (talk) 17:42, 4 October 2014 (UTC)
Discussion/Talk vs Info Desk vs Tea Room
1) The blank 'Discussion/Talk' page of every Wiktionary entry has apparently been superseded ambiguously by either an Info Desk or Tea page, with a very poor explanation and cumbersome connection/link or even directions to find the recommended edit page.
"Talk pages of individual entries are not usually monitored by editors, and messages posted there may not be noticed and responded to. You may want to post your message to the Tea Room or Information desk instead."
implies that there is another proper use for the convenient Discussion page, without acknowledging or describing what that might be.
"... may not be noticed and responded to." might mean "might not be noticed and responded to by anyone but subscribers to this entry."
I understand that the purpose of each entry's Discussion page is for the discussion of the critique of the article rather than the definition itself. Although I have seen no rational for the distinction, I presume it is to mitigate against the occasional very long educational debates that may obscure actual structural issues with the article.
2) Any improvements to this ubiquitous 'instruction' would apply across the (many) millions of entries which don't yet have discussion text. The rest (existing discussions) should presumably be moved to comply with this 'instruction'. This issue is apparently only a problem for relatively new users (of which I hope there are & will be many thousands more over the years). It would be nice if a convenient list of the dis/advantages & purposes of the Discussion page, were immediately visible or at the very least, linked in the 'instruction', so all users could maximize the benefit of their time and contributions.
3) Perhaps this discussion should be duplicated/linked on some Tea Room meta-page.
--Wikidity (talk) 00:56, 4 October 2014 (UTC)
please fix Module:headword to link multiword heads when head= is given
There's code in Module:headword (in format_headword) to automatically add links to each word of a multi-word page name, but it doesn't do this when an explicitly specified value is given using head=. This is important for Arabic because head= is used to specify the vocalized equivalent of a page name. You can work around this by manually adding the links, but I see no reason why this can't be done automatically. Can someone fix this? Or alternatively, can I be given permission to edit Module:headword so I can fix it myself? Thanks. Benwing (talk) 06:52, 5 October 2014 (UTC)
- This should not be done, because the
head=parameter is also used to suppress automatic linking. With your suggestion, there would be no way to do this anymore. —CodeCat 12:29, 5 October 2014 (UTC)- Hmmm, that means that head= has two different and potentially clashing uses, which is kind of ugly. Seems it would be better to have a separate param to suppress auto linking, maybe? Benwing (talk) 21:10, 5 October 2014 (UTC)
- Not really. The purpose is very clear: it overrides the default. Whatever you specify under
head=becomes what is displayed. —CodeCat 21:16, 5 October 2014 (UTC)
- Not really. The purpose is very clear: it overrides the default. Whatever you specify under
- Hmmm, that means that head= has two different and potentially clashing uses, which is kind of ugly. Seems it would be better to have a separate param to suppress auto linking, maybe? Benwing (talk) 21:10, 5 October 2014 (UTC)
another bug in Module:headword; please give me write permission to fix it
If you have two heads, both are displayed, but the transliteration is only for the first one, whereas it should show the transliteration of both, separated by "or", just like for the heads themselves. I'd like to have write permission on this module so I can fix bugs like this (and the one below, about cat2= and cat3=). Thanks. Benwing (talk) 09:14, 5 October 2014 (UTC)
- I've done this now. —CodeCat 14:42, 5 October 2014 (UTC)
- Thank you! Benwing (talk) 21:16, 5 October 2014 (UTC)
yet another bug in Module:headword
Only cat2= and cat3= are supported. No reason not to support at least up to cat9=. I feel this restriction acutely in some of the Arabic headword templates, and for this reason I have to manually insert the categories. Benwing (talk) 09:19, 5 October 2014 (UTC)
- I don't think it's much of a problem to manually insert categories in headword templates. —CodeCat 13:30, 5 October 2014 (UTC)
- But then you have to wrap it in namespace-checking
{{#if:}}s, which is tedious. — Keφr 14:52, 5 October 2014 (UTC)- Not if you use
{{catlangname}}or{{categorize}}. —CodeCat 15:15, 5 October 2014 (UTC)- What's the point of having cat2= and cat3= at all if we're only going to allow two of them? It should be trivial to fix this to allow more of them. If you don't want to bother doing this, why not remove cat2= and cat3= entirely instead of leaving a crippled interface in? Benwing (talk) 21:12, 5 October 2014 (UTC)
- That's a good point I suppose. But it makes me wonder why these additional parameters were originally added to the template, and why the choice was made at the time to include only 2. My guess is that they're only intended to be used for additional categories that pertain directly to the part of speech. For example, to have the main part of speech as "nouns" and to add "diminutive nouns" as a second. —CodeCat 21:15, 5 October 2014 (UTC)
- Probably just coding laziness, esp. since presumably this was originally coded using template hackery. Doing template hackery is so painful that coders routinely hardcode all sorts of arbitrary limits that shouldn't be there -- 2 of this, 3 of that, 5 of this, etc. Benwing (talk) 21:18, 5 October 2014 (UTC)
- I can add support for more categories, but I don't think they should be used for anything other than additional POS categories. So putting something like "slang" would not be right IMO. —CodeCat 21:36, 5 October 2014 (UTC)
- Probably just coding laziness, esp. since presumably this was originally coded using template hackery. Doing template hackery is so painful that coders routinely hardcode all sorts of arbitrary limits that shouldn't be there -- 2 of this, 3 of that, 5 of this, etc. Benwing (talk) 21:18, 5 October 2014 (UTC)
- That's a good point I suppose. But it makes me wonder why these additional parameters were originally added to the template, and why the choice was made at the time to include only 2. My guess is that they're only intended to be used for additional categories that pertain directly to the part of speech. For example, to have the main part of speech as "nouns" and to add "diminutive nouns" as a second. —CodeCat 21:15, 5 October 2014 (UTC)
- What's the point of having cat2= and cat3= at all if we're only going to allow two of them? It should be trivial to fix this to allow more of them. If you don't want to bother doing this, why not remove cat2= and cat3= entirely instead of leaving a crippled interface in? Benwing (talk) 21:12, 5 October 2014 (UTC)
- Not if you use
- But then you have to wrap it in namespace-checking
Entry templates
I created a new entry template for Hungarian nouns. How can I see it on the list of entry templates without changing the language preference? Currently, I see the Spanish and Swedish templates below the English ones. I'd like to keep English as the language of the interface. --Panda10 (talk) 13:18, 5 October 2014 (UTC)
SuggestBot?
Wikipedia's SuggestBot just gave me neat suggestions about what articles I might be interested in contributing towards. I have since added some of those to a "to-do list" in my userspace.
So, I'm wondering...
Does Wiktionary have a "SuggestBot" or something similar? Tharthan (talk) 21:04, 5 October 2014 (UTC)
Bad "transliteration needed" messages?
I made a change to Module:headword so that it tags and categorises entries that are not in Latin script, and which have no transliteration provided and none could be generated either. This seemed like a useful change, but apparently it's showing up in a few places where it's not wanted. I made exceptions for Chinese and Translingual. But I'd like to make sure there are no other cases of this. Could problems be reported here please? —CodeCat 00:00, 6 October 2014 (UTC)
- Japanese needs an exception too. It has automatic transliteration. See 消音器. --Anatoli T. (обсудить/вклад) 01:55, 6 October 2014 (UTC)
- It's not transliteration technically, as it's displayed as an inflection. So you're right. —CodeCat 02:08, 6 October 2014 (UTC)
- I've added the exception to Module:headword for ja following what you did for zh and mul. --Anatoli T. (обсудить/вклад) 02:17, 6 October 2014 (UTC)
- It's not transliteration technically, as it's displayed as an inflection. So you're right. —CodeCat 02:08, 6 October 2014 (UTC)
Importing offline dictionary
I was wondering if there are any automation tools/bots in existence that could import an offline dictionary file into wiktionary, supposing the formatting consistent and the license as CC. Me and a few friends are working on compiling a smallish dictionary for Oriya (Odia) in ABBYY's DSL format. I believe it'd be immensely useful if it could be imported into wiktionary. Coldbreeze16 (talk) 22:49, 7 October 2014 (UTC)
- I'd be happy to work on it- do you have any sample entries? DTLHS (talk) 04:15, 8 October 2014 (UTC)
- Thank you, and yes. http://pastebin.com/raw.php?i=fE52kQy9 That's a sample. A few words will be left undefined because source word list is EOWL and we don't have the resources to define every word in it (1,30,000 words). Coldbreeze16 (talk) 11:05, 8 October 2014 (UTC)
- @Coldbreeze16: Hm, any chance of getting it in a more convenient format? Or do you have any tools for converting to xml / json / etc? DTLHS (talk) 19:49, 9 October 2014 (UTC)
- Certainly! There's a standardized (partially) xml dictionary format called xdxf which offers a converter tool. Here's a snippet from the start of letter 'B'. http://pastebin.com/raw.php?i=QVb2P1DZ Coldbreeze16 (talk) 16:35, 10 October 2014 (UTC)
- @Coldbreeze16: Hm, any chance of getting it in a more convenient format? Or do you have any tools for converting to xml / json / etc? DTLHS (talk) 19:49, 9 October 2014 (UTC)
- Thank you, and yes. http://pastebin.com/raw.php?i=fE52kQy9 That's a sample. A few words will be left undefined because source word list is EOWL and we don't have the resources to define every word in it (1,30,000 words). Coldbreeze16 (talk) 11:05, 8 October 2014 (UTC)
Permission to run a bot?
I'd like to run a bot to fix up the parameters of various Arabic headword and link entries. There are a few tasks, e.g.
- Vocalizing unvocalized Arabic-script words based on the transliteration.
- Removing redundant transliterations.
- Removing various parameters from augmented verb headwords, because they're ignored (all relevant info can be auto generated given the numbered verb form).
I've never run a bot before but I have experience with Python, and I have some code from CodeCat that should help running the bot. I've converted the vocalization code in Module:ar-translit into Python and it works.
What needs to happen for me to get this set up and have the permissions enabled?
Thanks.
Benwing (talk) 10:41, 8 October 2014 (UTC)
Hello all. I have just edited the Lua module Module:la-headword in an attempt to add the optional function of listing a second genitive form, which is needed in the particular case of poppyzōn and which is useful generally. AFAICT, it hasn't introduced any errors and, for the most part, it works as intended. However, there is an undesirable comma between the first genitive form and the following "or" which I don't know how to get rid of. Could a more Lua-capable editor check my edit for any unforeseen errors and further edit the module to remove that offending comma, please? — I.S.M.E.T.A. 09:39, 10 October 2014 (UTC)
- I fixed it. The "or" is only used by the template
{{head}}. Internally in Lua, it's just a list. —CodeCat 11:20, 10 October 2014 (UTC)
- Thank you very much. I clearly have a lot to learn; Lua's pretty impenetrable for me ATM. — I.S.M.E.T.A. 21:55, 10 October 2014 (UTC)
- This is more a matter of our own modules than Lua itself. Module:headword's documentation is a bit out of date after several recent changes, and I need to update them but motivation is hard. :( —CodeCat 21:57, 10 October 2014 (UTC)
- You are kind, but I think you underestimate my coding incompetence! :-S Re documentation-writing motivation, I hear you; I only just got round to writing documentation for
{{R:OLD}}, and I still have{{R:Gaffiot}},{{R:Niermeyer}}, and{{R:Reaney & Wilson}}to do. — I.S.M.E.T.A. 16:29, 12 October 2014 (UTC)
- You are kind, but I think you underestimate my coding incompetence! :-S Re documentation-writing motivation, I hear you; I only just got round to writing documentation for
Some "transliteration needed" false positives
- Some entries have"Romaji"/"Rumi spelling"/"Latin spelling"/"Latin form" parameter
- code: bbc Category:Toba Batak terms needing transliteration
- code: bug Category:Buginese terms needing transliteration
- code: cia Category:Cia-Cia terms needing transliteration
- code: cjm Category:Eastern Cham terms needing transliteration
- code: ryu Category:Okinawan terms needing transliteration
- code: tgt Category:Central Tagbanwa terms needing transliteration
- code: tly Category:Talysh terms needing transliteration
Issues with Punctuation/Symbols in non-Latin scripts
code: en Category:English terms needing transliterationcode: shn Category:Shan terms needing transliterationcode: tl Category:Tagalog terms needing transliterationcode: za Category:Zhuang terms needing transliteration
Chuck Entz (talk) 00:36, 12 October 2014 (UTC)
- I'm not really sure how we could neatly solve those last 4... —CodeCat 00:40, 12 October 2014 (UTC)
- sc=Latn overrides the request, but may cause display issues. — Ungoliant (falai) 01:01, 12 October 2014 (UTC)
tr=-works too. But you'd have to do it for every entry. —CodeCat 01:03, 12 October 2014 (UTC)- That's probably the answer for the last 4: there's just a small, poorly delineated subset of many character sets that has no transliterations. The same holds for ideographic characters in cuneiform and hieroglyphs, too. It's not a huge number, so entering things by hand should work. Chuck Entz (talk) 01:17, 12 October 2014 (UTC)
- Those are fixed. The English Braille ones were actually caused by
{{meta-punctuation mark}}using{{head}}with no provision for a tr parameter. I added "|tr=-" and all of those disappeared from the category within seconds of my null edit to{{en-punctuation mark}}. Chuck Entz (talk) 01:59, 12 October 2014 (UTC)
- Those are fixed. The English Braille ones were actually caused by
- That's probably the answer for the last 4: there's just a small, poorly delineated subset of many character sets that has no transliterations. The same holds for ideographic characters in cuneiform and hieroglyphs, too. It's not a huge number, so entering things by hand should work. Chuck Entz (talk) 01:17, 12 October 2014 (UTC)
Search results
Would it be possible to "hide" the entry templates that appear in "Search results" so that you can see what appears underneath more easily? For example: https://en.wiktionary.orghttps://en.wiktionary.org/w/index.php?search=oppvaska&title=Special%3ASearch&go=Go . Donnanz (talk) 11:59, 14 October 2014 (UTC)
- I think the time may have passed when that screen was a default useful for the project. Can we find out how often it is used and how often the product is speedily deleted?
- In any event I would guess that Javascript could hide it. DCDuring TALK 12:22, 14 October 2014 (UTC)
- Quick note, a simple workround: put
#searchmenu-new-preload { display: none; }in your Special:MyPage/common.css to hide it for you. Dakdada (talk) 12:37, 14 October 2014 (UTC)- Thanks, I needed that. DCDuring TALK 13:35, 14 October 2014 (UTC)
- Quick note, a simple workround: put
- Ahem, has this gone onto the back burner? Donnanz (talk) 11:19, 31 October 2014 (UTC)
- It was unclear from your original request whether you wanted this to be the new default or whether you just wanted it for yourself. If you want it for a new default, it should go to the Beer Parlor as it is not a merely technical matter. DCDuring TALK 11:54, 31 October 2014 (UTC)
- I would like it to be possible for everyone to hide the entry templates on a temporary basis, via "hide" and "show" boxes. So if you want to refer this to the Beer Parlour, that's OK by me. Donnanz (talk) 12:08, 31 October 2014 (UTC)
- That's different. DCDuring TALK 12:19, 31 October 2014 (UTC)
- I would like it to be possible for everyone to hide the entry templates on a temporary basis, via "hide" and "show" boxes. So if you want to refer this to the Beer Parlour, that's OK by me. Donnanz (talk) 12:08, 31 October 2014 (UTC)
- It was unclear from your original request whether you wanted this to be the new default or whether you just wanted it for yourself. If you want it for a new default, it should go to the Beer Parlor as it is not a merely technical matter. DCDuring TALK 11:54, 31 October 2014 (UTC)
broken entry
- Discussion moved from Wiktionary:Tea room/2014/October.
the entry ad appears blank (in all wiktionaries). or is it just me? --Ninud (talk) 12:06, 15 October 2014 (UTC)
- You're right, this is strange. --WikiTiki89 12:24, 15 October 2014 (UTC)
- I have no problem seeing it using either Firefox 16.0.2 or Safari 5.0.6 (Mac). What browser are you using? Chuck Entz (talk) 12:38, 15 October 2014 (UTC)
- I'm using Google Chrome and I have Adblock Plus enabled, which I now realize may have something to do with the problem. --WikiTiki89 12:41, 15 October 2014 (UTC)
- I have confirmed that Adblock Plus is in fact the problem, since after disabling it the page displays correctly. I wonder how we can get around this problem. --WikiTiki89 12:44, 15 October 2014 (UTC)
- I was going to make a pun earlier about "adblockers", but bit my tongue. It would seem that truth is stranger than fiction! Seriously, though: Wiktionary has something to set off every text-based filter ever devised- should we even try to work around them? Chuck Entz (talk) 13:36, 15 October 2014 (UTC)
- oh, adblock was blocking ad ^^ thx guys --Ninud (talk) 14:25, 15 October 2014 (UTC)
- It is actually blocked in every language. We have the same issue on fr: on the same page fr:ad, see fr:Wiktionnaire:Wikidémie/août_2014#ad_est_tout_blanc. Someone said he created a bug report, but I don't know where. Dakdada (talk) 14:28, 15 October 2014 (UTC)
- Go to ad, click on the ABP button on your browser or otherwise fire it up. There's an option to "report a problem on this page". DCDuring TALK 15:24, 15 October 2014 (UTC)
- There is no such option for me (in Google Chrome). The only options are "Enabled on this site", "Block element", and "Ads blocked" ("0 on this page", which is strange since the whole page is blocked). --WikiTiki89 15:57, 15 October 2014 (UTC)
- Ok my report links to https://easylist.adblockplus.org/blog/2011/04/03/mediawiki-headers-and-ids. The problematic filter seems to be
##.page-ad. Dakdada (talk) 16:35, 15 October 2014 (UTC)- They didn't make it easy to report the issue for me either. In any event I've disable it for Wiktionary. DCDuring TALK 17:14, 15 October 2014 (UTC)
- Go to ad, click on the ABP button on your browser or otherwise fire it up. There's an option to "report a problem on this page". DCDuring TALK 15:24, 15 October 2014 (UTC)
- I was going to make a pun earlier about "adblockers", but bit my tongue. It would seem that truth is stranger than fiction! Seriously, though: Wiktionary has something to set off every text-based filter ever devised- should we even try to work around them? Chuck Entz (talk) 13:36, 15 October 2014 (UTC)
- I have confirmed that Adblock Plus is in fact the problem, since after disabling it the page displays correctly. I wonder how we can get around this problem. --WikiTiki89 12:44, 15 October 2014 (UTC)
- I'm using Google Chrome and I have Adblock Plus enabled, which I now realize may have something to do with the problem. --WikiTiki89 12:41, 15 October 2014 (UTC)
- I have no problem seeing it using either Firefox 16.0.2 or Safari 5.0.6 (Mac). What browser are you using? Chuck Entz (talk) 12:38, 15 October 2014 (UTC)
- My ABP button has the option "Disable on this page only", which worked for me on ]. Apparently Adblock Plus isn't aware of the use-mention distinction. —Aɴɢʀ (talk) 18:41, 15 October 2014 (UTC)
Pronunciation requests
I believe that we should change the entire "request for etymology/pronunciation" system. It shouldn't regularly be a "request". It should be like this:
Like the French Wiktionary has:
"Pronunciation?"
Beside words with incomplete pronunciation.
I think we should have something like that for every term that would need a pronunciation, and then have a category per language of all of the terms with pronunciations that are not added. A no-pronunciation-marker should be used when a term does not have an IPA, regardless of whether it has an audio clip, hyphenation, homophones, rhymes, or whatever else. Of course, for things like archaic terms we shouldn't have pronunciations for those, but it may be a good idea to mark these entries to let people know that their pronunciations are N/A. Just an idea, and it would help the site a lot.
Same thing for etymologies when they are missing.
Also, most etymologies, per the Wiktionary system, should have "From" at the beginning, and all etymologies need a period at the end of the sentence. I don't like seeing this: "
(section) Etymology (/section) mis + -calculation "
Anyway. So we should have bots put all these markers into the entries if we ever consider this idea.
My overall idea is: Have missing pronunciation not be a request, but rather treated as a need for (almost) all entries.
What do you guys think? Good idea, or bad idea? Rædi Stædi Yæti {-skriv til mig-} 20:16, 17 October 2014 (UTC)
 Generally, a resounding yes about missing pieces -- I think this is a great idea. I consider JA entries to be deficient until they have an etymology, pronunciation, POS and definitions, and where applicable,
Generally, a resounding yes about missing pieces -- I think this is a great idea. I consider JA entries to be deficient until they have an etymology, pronunciation, POS and definitions, and where applicable, {{ja-kanjitab}}and usage notes. References are big plus.- Pronunciations and etymologies should be something that we consider as a requirement for every entry, or at least every lemma entry. Beyond that, I would be in favor of coming up with some system of categorizing all elements required for each language's entries, and categorizing all entries that are missing any of these elements. ‑‑ Eiríkr Útlendi │ Tala við mig 05:00, 19 October 2014 (UTC)
- One thing I forgot to mention is that if we would use a system like this, we'd need to remake the rfe and rfp templates. We'd have to shorten the boxes so that they wouldn't take up so much space on entries. It would be great if we just had etymology incomplete to look something like this:
The etymology for this term is incomplete. If you are familiar with the etymology, please click here.
without a box and just the text. Maybe a small image too, but mainly the text is what I am worrying about.
We should make a similar template for pronunciation.
The reason I say incomplete is because a lot of entries may have *incomplete* etymologies or pronunciations. For instance, a term may have rhymes but no IPA (which is common on Wiktionary actually). An example of an incomplete etymology, which I also see a lot, is someone just putting:
French
as the etymology.
Anyway, you get that idea. We would probably also want to find some automated way to add the incomplete pronunciation templates, because there will be a lot of editors who may forget to put the templates, especially newer editors.
- Also, @Eirikr, I'm also very highly supporting the idea of adding pronunciations for non-lemma forms also. Someone may want to see the pronunciations of those also, especially if someone is not familiar with the language and only wants to know the pronunciation of that particular non-lemma form; even if it is for English itself. Rædi Stædi Yæti {-skriv til mig-} 07:02, 19 October 2014 (UTC)
- I oppose this rubbish now as before. --Dan Polansky (talk) 07:59, 19 October 2014 (UTC)
- Would you elaborate? It's not clear to me either why you think this is rubbish, or what "before" you are referring to. ‑‑ Eiríkr Útlendi │ Tala við mig 08:02, 19 October 2014 (UTC)
- This was discussed before. I oppose having empty pronunciation sections across the dictionary; that is an obvious rubbish and there is nothing to discuss, IHMO. Rædi Stædi Yæti is a troll or a semi-troll anyway, judging from multiple aspects of their editing behavior. By the way, pink 3D-rendered arrow to start a response is a rubbish as well. --Dan Polansky (talk) 08:11, 19 October 2014 (UTC)
- Re: "Pronunciations and etymologies should be something that we consider as a requirement for every entry, or at least every lemma entry": What a horrible piece of rubbish. The minimum content is definition, nothing else. Pronunciations are trivia, not serious lexicographical content. Requiring etymologies and pronunciations as a minimum would bring the expansion of useful content of Wiktionary to a halt. For instance, SemperBlotto would be unable to enter all the Latin content that he did. Try processing the dump to see how many lemma entries have both etymologies and pronunciations. --Dan Polansky (talk) 08:32, 19 October 2014 (UTC)
- Re "Pronunciations are trivia, not serious lexicographical content". Why do you spend time editing a dictionary when you so clearly have no interest in lexicography? Pronunciations are most definitely NOT trivia; they are the most essential part of any lexical entry, because written language is subordinate to and derived from spoken language. In fact, written language is not actually language any more than a painting of a pipe is a pipe. Written language is nothing but a convenient way of representing language, which (with the exception of sign languages) is spoken. As long as the pronunciation is known (which of course it isn't for many extinct languages), it is an indispensable part of the lexical entry—for nonlemmas as well as lemmas. Nevertheless, having ===Pronunciation=== sections with nothing in them is pointless, and having a bot flood them all with
{{rfp}}'s would render the{{rfp}}tag and the corresponding categories meaningless. Etymologies, on the other hand, are a different kettle of fish. They're interesting and should be included whenever they're known, but there should be no implication that they're a required component of an entry. Even in well studied languages like English, etymologies are often unknown, and for less well studied languages the research has often not been done. Editors should never be made to think, even indirectly, that they have to include etymological information, because that would encourage them to engage in their own etymological speculations. Our etymologies should always be backed up (or at least backable-up in principle) by scholarly research; when that is lacking or when the user doesn't have access to it, it's better to omit etymological information altogether. —Aɴɢʀ (talk) 12:47, 19 October 2014 (UTC)- For phonologically transparent languages like Czech word pronunciation is mostly irrelevant (you learn it together with the alphabet). For phonologically opaque languages like Russian and English it's much more important. Also, spoken language is only a minor subset of written language (lots of words are basically never spoken). I also suspect that most (>50%) of the communication today is done through written language exclusively. Almost everyone today is reading several times more words than they're talking/hearing... --Ivan Štambuk (talk) 17:20, 19 October 2014 (UTC)
- There are also words that are spoken but almost never written. And I am sure that people still talk more than they write and listen more than they read. --WikiTiki89 13:19, 20 October 2014 (UTC)
- For every developed language spoken vocab is at least an order of magnitude lesser than written vocab. Spoken words that have never been written only exist for minor languages with few native speakers, where literacy is an issue. Average person reads text at least 2-3 times faster than they can speak, so even though they spend more time communicating verbally, at the end of the day much more is absorbed by reading. Furthermore, spoken language is of very limited lexicon, and in terms of distinct words communicated over some period, written language wins hands down. Most of English pronunciations for obscure words are hypothetical since probably none of the editors has heard them spoken, or is likely to do so. Advent of personal digital assistants capable of speech processing is unlikely to reverse the trend. --Ivan Štambuk (talk) 17:56, 20 October 2014 (UTC)
- Aren't the words, which we seldom hear spoken, still pronounced in our minds? Pronunciations are important, especially for words we don't hear. E.g. there are borrowings from Chinese pinyin and people often wonder how to say them (even if there are variants and no established standard). --Anatoli T. (обсудить/вклад) 22:47, 20 October 2014 (UTC)
- For every developed language spoken vocab is at least an order of magnitude lesser than written vocab. Spoken words that have never been written only exist for minor languages with few native speakers, where literacy is an issue. Average person reads text at least 2-3 times faster than they can speak, so even though they spend more time communicating verbally, at the end of the day much more is absorbed by reading. Furthermore, spoken language is of very limited lexicon, and in terms of distinct words communicated over some period, written language wins hands down. Most of English pronunciations for obscure words are hypothetical since probably none of the editors has heard them spoken, or is likely to do so. Advent of personal digital assistants capable of speech processing is unlikely to reverse the trend. --Ivan Štambuk (talk) 17:56, 20 October 2014 (UTC)
- There are also words that are spoken but almost never written. And I am sure that people still talk more than they write and listen more than they read. --WikiTiki89 13:19, 20 October 2014 (UTC)
- For phonologically transparent languages like Czech word pronunciation is mostly irrelevant (you learn it together with the alphabet). For phonologically opaque languages like Russian and English it's much more important. Also, spoken language is only a minor subset of written language (lots of words are basically never spoken). I also suspect that most (>50%) of the communication today is done through written language exclusively. Almost everyone today is reading several times more words than they're talking/hearing... --Ivan Štambuk (talk) 17:20, 19 October 2014 (UTC)
- Re "Pronunciations are trivia, not serious lexicographical content". Why do you spend time editing a dictionary when you so clearly have no interest in lexicography? Pronunciations are most definitely NOT trivia; they are the most essential part of any lexical entry, because written language is subordinate to and derived from spoken language. In fact, written language is not actually language any more than a painting of a pipe is a pipe. Written language is nothing but a convenient way of representing language, which (with the exception of sign languages) is spoken. As long as the pronunciation is known (which of course it isn't for many extinct languages), it is an indispensable part of the lexical entry—for nonlemmas as well as lemmas. Nevertheless, having ===Pronunciation=== sections with nothing in them is pointless, and having a bot flood them all with
- @Angr The notion that language being primarily spoken makes pronunciation "the most essential part of any lexical entry" (boldface mine) can hardly get more bizzare, IMHO. It suggests that an entry with a pronunciation but no definitions and example sententences is better than an entry with no pronunciation but extensive definitions, example sentences and translations into dozens of languages. That, to me, seems patently absurd. As for the manner of argument you have chosen: even in dictionaries that provide pronunciation, readers do not have indexing and searching by pronunciation; rather, indexing and searching is by the written forms of words. Even in the age of computers, most dictionary users do not know how to mark up pronunciation, so they cannot enter pronunciation markup into a search field and hope to find what they were looking for. I rest my case that it is the headword with definitions that is the sole essential part of any entry. As for those who believe that it is urgent that each English lemma has a pronunciation markup, they are free to bind their resources to add it, not the resources of other editors. --Dan Polansky (talk) 10:18, 25 October 2014 (UTC)
- Would you elaborate? It's not clear to me either why you think this is rubbish, or what "before" you are referring to. ‑‑ Eiríkr Útlendi │ Tala við mig 08:02, 19 October 2014 (UTC)
- Disagree about "From" in every etymology. It's unnecessary and I faintly resent people adding it to mine. (I mean, an etymology by definition is where a word is from. We don't put "Sounds like" at the start of pronunciation lines, or "Means" at the start of sense lines.) Equinox ◑ 10:11, 22 October 2014 (UTC)
- There is always an implied "is" (or "was"):
- "bed" is /bɛd/
- "bed" is a piece of furniture for sleeping on.
- "bedroom" is bed + room
- "bed" is from Old English bedd
- In the last example, the implied "is" is not enough. --WikiTiki89 10:58, 22 October 2014 (UTC)
- There is always an implied "is" (or "was"):
![]() "Rubbish" aside, at least some of us editors appear to be keen on having better visibility for entries that are missing various kinds of data. I understand that there is resistance to the idea of adding
"Rubbish" aside, at least some of us editors appear to be keen on having better visibility for entries that are missing various kinds of data. I understand that there is resistance to the idea of adding {{rfp}}, {{rfe}}, etc. all over the place. I can empathize with that concern, in part because visual clutter is bad for usability. As an alternative idea for improving this kind of visibility for editors without changing the entries themselves (at least visually), is there any easy way of generating lists of terms in XX language that are missing headers YY, ZZ, and WW? In addition, is it possible to get a list of terms in XX language that are missing AA, BB, and CC templates? Finding what terms have any given template is extremely easy, but finding terms that don't have that template is a bit of a challenge. Right now, all I can think of to do this would be to analyze a database dump -- which isn't very user-friendly (where "users" in this context refers to us editors). ‑‑ Eiríkr Útlendi │ Tala við mig 17:26, 30 October 2014 (UTC)
- Something I have been considering is to make a complete parser for Wiktionary specifically. There's already mwparserfromhell, but that only does general "flat" token-based parsing and it doesn't know anything about our entry structure. Nonetheless it serves as a useful base to make larger building blocks. It would also be useful for error checking, as any malformed entry (header or template in the wrong place, etc.) could be caught by it. —CodeCat 17:34, 30 October 2014 (UTC)
- I haven't read all of the comments above, but the French system is basically to always include an
{{IPA}}template (called fr:Template:pron) in every language section. Of course the vast majority don't include a pronunciation! However they (or should I say 'we'; I've been editing there longer than I've edited here) don't (usually) put it in a pronunciation section, so we'd be including extra empty sections where they don't. We could do it purely to get every entry into Category:English entries needing pronunciation (or whatever language) but I think having millions of extra empty ===Pronunciation=== sections outweighs the benefit. But I don't feel strongly enough about it to actually oppose it. Renard Migrant (talk) 17:43, 30 October 2014 (UTC)
- I haven't read all of the comments above, but the French system is basically to always include an
Dewikifying JS
I run into cases from time to time where the system has parsed wikitext in Javascript files, with resulting oddities showing up in Special:WantedCategories, Special:WantedTemplates, etc.
While this is only a minor annoyance, the solution is very simple: we should make it standard practice to put //<nowiki> as a line near the top of every .js page, and //</nowiki> as a line at the bottom. As comments, these won't affect Javascript execution, but will keep the system from interpreting the pages as wikitext.
This presupposes, of course, that there isn't a better way to do this- but we should do something just to be on the safe side. Chuck Entz (talk) 21:56, 18 October 2014 (UTC)
- Well, we could ask the developers at bugzilla: to stop preprocessing and parsing JavaScript files to find links. However, there might be opposition to this, since this feature has at least one useful use case: it can be used to track users of custom scripts. If someone puts in their Special:MyPage/common.js, it will put their common.js on the backlinks list of the script. Which may be useful sometimes.
importScript('User:Kephir/gadgets/xte.js'); // ]
- But as for the original suggestion, I have no objections. I think you can add it to Wiktionary:Coding conventions. I will only note the
// </nowiki>is not actually necessary. Omitting it does not cause any errors and I doubt anything will change in that regard. — Keφr 11:52, 19 October 2014 (UTC)
Accessibility issue with quotations link
Discussing Wiktionary at the Oxford Wikimedia meetup, it has been pointed out that the "quotations" link to the right of an entry (e.g. at hoaxical#Adjective) is too small to be read by people with poorer than average eyesight. I'm told that the WCAG is that text should not be smaller than 85% of the normal font size. Assuming the standard text size is 11pt this means the font size should not be lower than 9.35pt but the quotations link is 8.25pt, and so should be increased. See also Wikipedia's accessibility guidelines.
By all means have a preference to make it smaller, but it needs to be large enough by default for users who are not logged in. Thryduulf (talk) 13:23, 19 October 2014 (UTC)
- See w:MOS:ACCESS#Text "in no case should the resulting font size drop below 85% of the page fontsize". --Redrose64 (talk; at English Wikipedia) 08:50, 20 October 2014 (UTC)
Is it just me or is the Watchlist now displaying every edit to a watched page as opposed to the most recent edit? I think I might like this new feature, but I'm also curious whether there is an option to disable it temporarily or anything like that. --WikiTiki89 20:44, 21 October 2014 (UTC)
- Never mind, it only did that once and when I refreshed, it went back to normal. This is strange... --WikiTiki89 20:45, 21 October 2014 (UTC)
- "Expand watchlist to show all changes, not just the most recent" in Special:Preferences#mw-prefsection-watchlist controls this, I believe. — Keφr 20:47, 21 October 2014 (UTC)
- Yep, thanks! I didn't realize that was an option. So if I have it enabled in prefs, is there a way to temporarily disable it without changing my prefs (similar to the "hide minor edits", etc. options)? --WikiTiki89 21:33, 21 October 2014 (UTC)
- It suddenly happened to me too. I think that option went from being off as default to being on as default. —Aɴɢʀ (talk) 22:07, 21 October 2014 (UTC)
- Yep, thanks! I didn't realize that was an option. So if I have it enabled in prefs, is there a way to temporarily disable it without changing my prefs (similar to the "hide minor edits", etc. options)? --WikiTiki89 21:33, 21 October 2014 (UTC)
- "Expand watchlist to show all changes, not just the most recent" in Special:Preferences#mw-prefsection-watchlist controls this, I believe. — Keφr 20:47, 21 October 2014 (UTC)
amortajadas and probably hundreds of others
The page amortajadas currently looks very ugly. I'm guessing there was a change in a template, but I can't track it down. Any ideas? --Type56op9 (talk) 09:52, 25 October 2014 (UTC)
- Fixed. It seems
{{es-verb form of}}should be migrated to Module:form of or something. User:CodeCat? — Keφr 10:46, 25 October 2014 (UTC)
Wikisaurus
(NOTE: I'm not sure if this should go in the Beer Parlour or here, so feel free to move it if it is improperly placed.)
I'm not suggesting that we move Wikisaurus or anything like that, but I do have a question:
What was the reasoning for having Wikisaurus be but a limb of Wiktionary, when (in many real life cases) thesauri are often seperate publications from dictionaries? Tharthan (talk) 13:12, 25 October 2014 (UTC)
- In print, dictionaries and thesauruses have vastly different organizational needs. If dictionaries had room for it, they would all have a thesaurus in the appendix. We, however, are not limited by space. One of our problems is that we have to approaches to being a thesaurus: we have the WT:Wikisaurus and we have the mainspace ====Synonyms==== and ====Antonyms==== sections. Ideally (in my opinion), we'd be able to get rid of Wikisaurus by including everything in mainspace. This doesn't really belong at either the GP or the BP, but I'm not going to bother moving it to the WT:ID. --WikiTiki89 13:25, 25 October 2014 (UTC)
- One thing that an extended thesaurus-type presentation could accomplish that would just clutter up a dictionary entry would be to show in close proximity several words which are considered synonyms together with any slightly different meanings or different usage contexts (broadly defined (to include syntactical relationships, time periods, regions, registers) or associations ("connotations" or allusions). Note that this is not what print thesauruses usually do: they offer bare lists that are apparently intended to present possible substitute words or associated words, whose precise differences in meaning and other attribute need to be found or confirmed in a dictionary. IMO Wikisaurus takes an approach that is too similar to those of our Synonyms sections and of print thesauruses. DCDuring TALK 16:47, 26 October 2014 (UTC)
Does This Template Already Exist?
I would like to ask whether a particular very simple table (table only, no content) already exists. It would look like this Norwegian Inflection table, except simpler: https://en.wiktionary.orghttps://dictious.com/en/time#Inflection_2
- In the top row, it would say "Possession of" instead of "Inflection of"
- In the second row, the column headers would be only "singular" and "plural" (instead of indefinite singular/def.singular/indef. plural/def.plural)
- In the third row, the row header would be "1st person"
- In the fourth row, the row header would be "2nd person"
- In the fifth row, the row header would be "3rd person"
That's all. Just six table cells that I can fill in for each possessed noun. I would like to use it instead of the bullet list under Inflection on this page: https://en.wiktionary.orghttps://dictious.com/en/amunaun Does anyone know if such a table already exists? Thanks. Emi-Ireland (talk) 04:06, 26 October 2014 (UTC)
- @Emi-Ireland I have created
{{wau-possession}}. Let us know if anything needs to be changed. — Ungoliant (falai) 14:34, 26 October 2014 (UTC)
You people are really amazing. Thank you SO MUCH! Emi-Ireland (talk) 14:39, 26 October 2014 (UTC) It works perfectly. Really nice and clean. Should I also copy the template to Wauja language templates? Or is it stored in some centralized location? Thanks Emi-Ireland (talk) 20:08, 27 October 2014 (UTC)
- Do you mean to Wauja templates for other types of inflection, or to other words that inflect for possession? — Ungoliant (falai) 20:20, 27 October 2014 (UTC)
Yes, I was thinking this would work well for a simple verb conjugation table, which can hold basic conjugation information. This table would also be suitable for personal pronouns. I've coded lots of complex tables in HTML and CSS, so I might be able to get the hang of this. However, when I looked at the template in Edit mode, I saw very clear instructions on using the template (thanks for that), but not the code that generates the table itself. Where is the code that generates the template located? Meanwhile, I will keep reading the Help section on templates. Thanks very much.71.178.188.4 13:36, 28 October 2014 (UTC)
- What you are actually seeing is the documentation of the template. If you click edit you can see the code ().
- If the conjugation of Wauja is very complex, it may be a better idea to make templates that generates the conjugation table based on the inflection paradigm so that you don’t have to type up all the forms manually. For example, in Portuguese we can use
{{pt-conj|ach|ar}},{{pt-conj|com|er}}and{{pt-conj|emit|ir}}for the conjugations of achar, comer and emitir. — Ungoliant (falai) 15:07, 28 October 2014 (UTC)
search error
Right now if I search on Wiktionary for an entry which does not exist (a red-link entry) I get the following error report: An error has occurred while searching: Search is currently too busy. Please try again later. But this does not come up if I search for something which already has an entry. I tried to refreshing my browser cache to no avail. What's going on? ---> Tooironic (talk) 12:46, 27 October 2014 (UTC)
- I get it too. It's OK if you click on a red inflection within an existing entry. I can create an entry that way. Donnanz (talk) 12:54, 27 October 2014 (UTC)
- It seems to me that it, if you believe the message, it is highly likely to also occur on some successful searches. A failed search has, on average, more work to do than a successful one. This would be especially true if some portion of our entries were not keyed efficiently and therefore required slower search. Every unsuccessful search would have to search that unkeyed list, but very few successful ones would have to. DCDuring TALK 15:02, 27 October 2014 (UTC)
- I thought the problem had been cured, but it's still occurring occasionally, with the same error message. A bug must have developed somewhere. Donnanz (talk) 17:26, 27 October 2014 (UTC)
- My searches never turn up anything anymore. If I type in a page name that exists, it goes straight to it. If the page name does not exist, I get no results. It's maddening. Renard Migrant (talk) 18:44, 27 October 2014 (UTC)
- Maddening indeed. I got the same error message (written in Norwegian) on Norwegian Wiktionary, looking for radiostyrt. Mind you, I didn't expect the word to be in there. Donnanz (talk) 19:09, 27 October 2014 (UTC)
- Could nowikt and enwikt be on the same server group? I didn't get such results on WP. I get all of the results: direct to entry, list of entries with the term(s), and HTTP timeout error, using just basic ASCII characters and near-words. I do seem to get the timeout error very quickly, just a few seconds, so perhaps some timeout limit has been changed, perhaps only on one groups of servers. DCDuring TALK 19:15, 27 October 2014 (UTC)
- Maddening indeed. I got the same error message (written in Norwegian) on Norwegian Wiktionary, looking for radiostyrt. Mind you, I didn't expect the word to be in there. Donnanz (talk) 19:09, 27 October 2014 (UTC)
- My searches never turn up anything anymore. If I type in a page name that exists, it goes straight to it. If the page name does not exist, I get no results. It's maddening. Renard Migrant (talk) 18:44, 27 October 2014 (UTC)
- I thought the problem had been cured, but it's still occurring occasionally, with the same error message. A bug must have developed somewhere. Donnanz (talk) 17:26, 27 October 2014 (UTC)
- It seems to me that it, if you believe the message, it is highly likely to also occur on some successful searches. A failed search has, on average, more work to do than a successful one. This would be especially true if some portion of our entries were not keyed efficiently and therefore required slower search. Every unsuccessful search would have to search that unkeyed list, but very few successful ones would have to. DCDuring TALK 15:02, 27 October 2014 (UTC)
- The problem went away for a few days, but now it's back again. Donnanz (talk) 11:17, 31 October 2014 (UTC)
I just change the plural of archal to archaux, because {{fr-noun}} is giving it the automatic plural archaaux! Hopefully this is just a type in Module:fr-headword. Can some correct it? Whatever and wherever it is. Renard Migrant (talk) 18:16, 27 October 2014 (UTC)
- I fixed it. It wasn't a typo as much as a thinko, or maybe an off-by-one error. —CodeCat 18:19, 27 October 2014 (UTC)
Extra space at the top
Can someone get rid of the extra space at the top of qroqqa? This, that and the other (talk) 09:58, 30 October 2014 (UTC)
 Done by moving the word-of-the-day thing underneath the picture. Equinox ◑ 14:02, 30 October 2014 (UTC)
Done by moving the word-of-the-day thing underneath the picture. Equinox ◑ 14:02, 30 October 2014 (UTC)
- That's a workaround, not a fix. I would like to see a fix, because I tried very hard unsuccessfully to figure out what was causing it. --WikiTiki89 16:13, 30 October 2014 (UTC)
- Not sure if this counts as a fix or a workaround, but I just added a floating div to contain the FWOTD and image. This fixes the layout (removes the whitespace) without changing the order of elements as seen on the page. The underlying problem has to do with how different kinds of HTML block elements interact with each other. ‑‑ Eiríkr Útlendi │ Tala við mig 17:07, 30 October 2014 (UTC)
- Huh? I see no weird space in the old version (using latest Firefox, even with Tabbed Languages disabled). — Keφr 17:33, 30 October 2014 (UTC)
- Interesting. Firefox appears to be the "nicer" layout for this. For that old version, Chrome shows a single line of blank space vertically between the language header and the Etymology header. Meanwhile, IE shows a huuuuge amount of blank space, as if the FWOTD and image were left-aligned instead of on the right where they actually appear. I might be able to test in Safari later today, if anyone's interested. ‑‑ Eiríkr Útlendi │ Tala við mig 17:59, 30 October 2014 (UTC)
- I've reduced this to a simple test case: see .


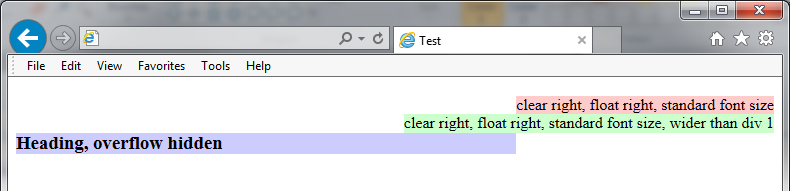
- There are still a lot of factors in this test case - perhaps somebody can narrow it down further? Keith the Koala (talk) 11:02, 31 October 2014 (UTC)


