Bonjour, vous êtes venu ici pour chercher la signification du mot Wiktionnaire:Wikidémie/mars 2018. Dans DICTIOUS, vous trouverez non seulement toutes les significations du dictionnaire pour le mot Wiktionnaire:Wikidémie/mars 2018, mais vous apprendrez également son étymologie, ses caractéristiques et comment dire Wiktionnaire:Wikidémie/mars 2018 au singulier et au pluriel. Tout ce que vous devez savoir sur le mot Wiktionnaire:Wikidémie/mars 2018 est ici. La définition du mot Wiktionnaire:Wikidémie/mars 2018 vous aidera à être plus précis et correct lorsque vous parlerez ou écrirez vos textes. Connaître la définition deWiktionnaire:Wikidémie/mars 2018, ainsi que celles d'autres mots, enrichit votre vocabulaire et vous fournit des ressources linguistiques plus nombreuses et de meilleure qualité.
Ce mois-ci, je vous propose de nous intéresser aux mathématiques et à tout le vocabulaire qui concerne cette discipline ! C’est que, le 14 mars, ce sera le jour de Pi (un calcul qui marche mieux avec le format de date américain : 3/14) ! Pour l’occasion, voyons que mettre dans un nouveau thésaurus sur les mathématiques à inventer, qui sera peut-être une porte d’entrée vers d’autres thésaurus pour les branches de la discipline !
L’idée de la LexiSession est de proposer un thème par mois à l’ensemble des Wiktionnaires afin d’avancer conjointement sur un même sujet et d’apprendre par l’observation des pratiques des autres, et par le contenu créé sur un thème que l’on découvre, dans d’autres langues. Cette initiative est ouverte à tous et les sujets peuvent être proposé sur cette page de Meta !
Si le thème vous intéresse, vous pouvez indiquer ce que vous faites autour de celui-ci durant le mois ou à la fin. Si vous le pouvez, allez prévenir les autres Wiktionnaires dans leurs langues, pour qu’ils se joignent à l’aventure ! Les LexiSessions ont besoin de relais ! Noé1 mars 2018 à 09:28 (UTC)
Bonjour. Je copie ici mon message laissé un peu plus tôt sur Meta : Une annonce sur le Thé pourrait faire venir des contributeurs.
Que mettre dans le thésaurus ? Je me suis permis de déplacer la discussion sur quoi mettre dans le thésaurus sur la page de discussion. Si cela vous dérange, vous pouvez la remettre ici Delarouvraie🌿5 mars 2018 à 09:08 (UTC)
LexiSession en page d’accueil
La section Travail collaboratif de la semaine est rarement remplie, aussi je vous propose de la remplacer par la LexiSession du mois. Qu’en dites-vous ? Noé1 mars 2018 à 18:56 (UTC)
PourJona (discussion) 2 mars 2018 à 09:52 (UTC) Je me disais aussi qu'il était temps d'agir au sujet de la section Travail collaboratif de la semaine sur la page d’accueil qui est trop souvent vide.
Ok, j’étais partis pour mais… @JackPotte : je ne sais pas comment faire pour que les LexiSessions n’apparaissent que lorsqu’il n’y a pas de projet de la semaine. J’allais supprimer la section de la page d’accueil, mais si tu sais faire mieux, alors je te laisse faire Noé10 mars 2018 à 19:07 (UTC)
Heu…je n’ai pas très bien compris ce que tu as fait, ni où je peux indiquer la LexiSession en cours. Un petit peu plus d’explications ? Noé10 mars 2018 à 20:30 (UTC)
Ce modèle que je viens de créer s'affiche sur la page d'accueil quand aucune collaboration de la semaine n'est définie. JackPotte ($♠) 10 mars 2018 à 20:51 (UTC)
Actualités du Wiktionnaire, numéro 35 de février 2018
Le dernier numéro des Actualités du Wiktionnaire est arrivé ! Retrouvez ici le numéro 35 de février 2018.
Un numéro complétement givré des Actualités avec des brèves surprenantes et des statistiques qui réchauffent. Trois articles donnent corps à ce numéro : les alliés des wiktionnaristes, un dictionnaire documenté et un orque qui parle ! Et comme d’habitude, des infos sur les nouveautés du Wiktionnaire du mois écoulé et des conseils de vidéos à regarder pour patienter jusqu’au prochain numéro ! Et sept plumes ont participé cette fois-ci !
Vous pouvez participer au prochain numéro si vous le souhaitez !
Ah oui, je précise : comme il y a des articles signés, vous pouvez apporter des réponses et d’autres points de vue sur les points déjà abordés. Comme il n’y a pas d’exigence de rentabilité, cet espace est vraiment ouvert à toutes les plumes ! De nombreuses personnes ont déjà ajouté des articles occasionnellement et ça n’engage à rien sur le long terme. Ah et vous ne serez pas rémunéré. Je ne l’ai peut-être pas précisé, mais depuis les débuts des Actualités, personnes n’a été payé pour les écrire. C’est tout à fait bénévole, de A à Z Noé1 mars 2018 à 18:56 (UTC)
Nouveau logo en 3D des Wiktionnaires (version occidentalo-centrée)
Joli . Il me semble que seuls les navigateurs modernes sont capables de prendre en charge les images 3D. Pamputt4 mars 2018 à 10:39 (UTC)
Chouette ! Je ne savais pas que mon navigateur pouvait afficher des objets en 3D. Tu as un tutoriel qui expliquerait comment en créer d’autres ? Romainbehar (discussion) 4 mars 2018 à 16:26 (UTC)
Romainbehar (d · c · b) Je me suis servi d’Inkscape et de l’extension Inkscape to OpenSCAD converter v7 et enfin de OpenSCAD. Le plus difficile c’est de réfléchir à comment doit être la forme 3D. Pour les tutos sur OpenSCAD, il y a cette chaîne youtube. Après j’aimerai voir pour faire de meême avec des photographies mais ça c’est pas le même logiciel. Otourly (discussion) 4 mars 2018 à 17:45 (UTC)
Bon les gens, je m’ennuyais alors j’ai fait ça. Faudrait sûrement améliorer tout ça (la section arme est trop petite à mon goût, et il faudrait illustrer), mais là j’en ai ma claque pour la journée. ^^ --— Lyokoï (Discutons) 4 mars 2018 à 15:58 (UTC)
Salut les patrouilleurs !! Je tiens à vous rappeler qu’il y a un bulletin dédié la discussion entre nous ! N’hésitez pas à le mettre dans votre liste de suivi ! D’ailleurs si je fais un message ici, c’est parce que j'ai l'impression que le message de JackPotte (d · c · b) n'a pas eu beaucoup d’effet. Nous avons besoin de vous en ce moment pour vérifier les modifications des nouveaux. N'hésitez pas à faire quelques petits passages réguliers de temps en temps, ça apporte un vrai plus à la qualité du Wiktionnaire. Merci d’avance ! #Wikilove --— Lyokoï (Discutons) 4 mars 2018 à 23:59 (UTC)
]
]">modifier le wikicode]
Bonjour Mimich a développé (et utilise) le modèle {{modl|eo-form-conj}}. Je suis tombé dessus en regardant la page daŭrigate. En regardant le code de la page, je ne sais pas si on a une convention sur le sujet mais je pense qu’un modèle dans lequel est caché tout l’article n’est pas souhaitable car ça rend encore plus inaccessible le Wiktionnaire aux nouveaux contributeurs qu’il ne l’est déjà. Bref, le tableau de flexion peut évidemment s’appeler à partir d’un modèle mais en ce qui concerne la « définition », je pense que ça devrait être écrit en toute lettre. Vos avis sur ce sujet ?
Au passage le modèle est boggué car il affiche « daŭrig » sur la ligne de forme et pas « daŭrigate ». Mais ça se corrige . Pamputt5 mars 2018 à 18:13 (UTC)
daŭrigate est corrigé. J’ai développé ce modèle uniquement pour standardiser et faciliter la très répétitve composition des pages des formes de verbes. Il suffit de changer quelques lettres qui composent le code temps et l’on peut faire les dites formes facilement "en rafale". Je ne l’emploie pas pour la page principale du verbe. On peut peut-être préciser voire imposer la chose dans le modèle. Je viens d’y ajouter une option "texte libre" en face de la ligne principale et rien n’empêche d’écrire des choses en plus en-dessous des éléments principaux. Pour que vous vous fassiez une idée, cela concerne déjà 3696 formes de verbes (236 verbes dont 57 intransitifs). Dont certaines sont classées selon leur caractère fondamentale grâce au modèle également !!! --Mimich (discussion) 5 mars 2018 à 18:45 (UTC)
Sauf que ça rend le code de l’article illisible par un robot également. Cela contrevient à nos conventions de mise en forme. --— Lyokoï (Discutons) 5 mars 2018 à 22:13 (UTC)
@Mimich : Effectivement, ça contrevient aux conventions de mise en forme, et ça empêche ou gêne sérieusement l’exploitation par programmes. Si on veut accélérer les créations, il vaut mieux créer un robot (ou des robots) qui génèrent des pages formatées de façon standard, il y a des chances pour que ça aille encore beaucoup plus vite. Ce genre de robot existe pour plusieurs langues, pourquoi pas l’espéranto. Lmaltier (discussion) 6 mars 2018 à 06:40 (UTC)
Plein de pages sur des mots en langues slaves indiquent que les mots proviennent du vieux-slave, par exemple voda, dan#sl, gęś, cudzí, člověk, etc. Je suis très dubitatif de ces étymologies : le vieux-slave n'est pas l'ancêtre des langues slaves, mais seulement du macédonien et du bulgare, et donc un cousin des autres langues slaves. L'ancêtre de toutes les langues slaves est le proto-slave. Les autres langues slaves ont certes emprunté des mots au vieux-slave, mais je doute par exemple que le tchèque lui ait emprunté des centaines de mots. Bref, des centaines (voir des milliers) de pages ont des informations étymologies douteuses. Que faut-il faire ? Remplacer automatiquement "vieux slave" par "proto-slave" dans les pages concernées ? Mutichou (discussion) 5 mars 2018 à 20:25 (UTC)
Je rejoins Lyokoï, il nous faut des sources pour bien faire. Si le doute est modéré, je pense qu’il serait pertinent d’ajouter un modèle demandant une source pour attester de l’assertion étymologique. Si le doute est vraiment fort, je ne trouverait pas abusif de supprimer l’assertion et de mettre un modèle indiquant que des contributions sourcés sont les bienvenues. Par contre je ne trouverait pas judicieux de simplement remplacer les assertions sans ajouter de source. Dans un premier temps, une démarche possible serait de faire une page projet dédié et d’y lister les articles concernés. En tout les cas, merci pour cette remontée d’information @Mutichou :. --Psychoslave (discussion) 6 mars 2018 à 09:59 (UTC)
Si il y a une controverse lexicographique sur un jeu d’entrée assez large, une solution c’est de concevoir une page dédié dans un espace de nom approprié, et de développer la problématique et les différentes thèses courantes sur le sujet, le tout avec des liens pour sourcer et aller plus loin. Une fois une telle page réalisé, un modèle spécifique pourrait être envisagé pour mettre un texte et un lien idoine dans toutes les entrées étymologiques proposés. Qu’en dites vous ? Je précise que je n’ai pas d’avis sur la problématique vieux-slave/proto-slave en elle-même, pour laquelle j’avoue bien humblement ma totale ignorance (cela dit le débat donne l’envie de se renseigner plus avant). C’est bien sur la démarche de façon générale que je pose la question. --Psychoslave (discussion) 6 mars 2018 à 11:55 (UTC)
Il n'y a pas de controverse, personne dans le milieu scientifique ne soutient que le vieux-slave est l'ancêtre de toutes les langues slaves.
Je viens de constater que la définition que nous proposons pour banque de données correspond mot pour mot à celle de FranceTerme, et pour cause c’est de là qu’elle provient, comme le stipule les références. FranceTerme est diffusé sous licence ouverte, qui requière uniquement que la source soit cité. Donc en l’état, nous sommes dans les clous. Par contre il y a des améliorations possibles :
ce serait bien que d’une manière ou d’une autre quelle définition provient d’où soit explicitement indiqué. En l’occurrence il n’y en a qu’une pour cette entrée, donc c’est moins problématique, mais la démarche n’est pas générique.
les ré-utilisateurs des données du Wiktionnaire devraient également être informé de la licence de la définition. Ce n’est en soi pas une obligation légale, mais ça permet d’être plus claire sur les obligations de ceux qui rediffusent ces définitions. Bon, comme dans le cas du Wiktionnaire de façon générale il y a obligation de fournir source et licence du fait des clauses de la CC-by-sa, il me paraît moins probable qu’un tiers réutilise en toute bonne fois l’œuvre sans tenir compte des clauses d’utilisation.
Dans empire il y a deux exemples avec sous, sans explication sur emprise. Dans emprise la note parle d’empreinte (!) là où j’attendais empire. Je ne vois pas ce qu’empreinte fait ici, vu que dans empreinte rien ne correspond à ce sens.
C’est bon ! J'ai enfin mis en ligne la captation de ma conférence sur l’histoire du Wiktionnaire. Bon, c’est résumé en 20 minutes, et j’aimerais bien entendre tous vos avis, vos anecdotes, etc. Bon visionnage ! — Lyokoï (Discutons) 7 mars 2018 à 08:01 (UTC)
Oui c’est assez court cela dit, je pense que les « grandes périodes » de l’histoire du Wiktionnaire sont clairement évoquées ; c’est un très beau travail de plongée dans les archives que tu as réalisé Lyokoï, félicitation. Ca pourra toujours servir de base à un travail plus poussé. Pamputt7 mars 2018 à 21:26 (UTC)
@Romainbehar : Mr Catach était très intéressé ! Nous avons eu de bons échanges avec lui. Tu dois pouvoir trouver sa conférence sur youtube.
@Pamputt : J'étais l'imité dans le temps qui m'était donné, j'ai donc fait ce que j'ai pu. Merci pour le compliment ! J'ai fait ça parce que justement, l’histoire de notre projet est trop peu connue, notamment par les membres les plus récents et qu'il est très difficile de trouver l’information. Cette conférence est donc un premier point de départ pour qui voudra chercher plus loin. --— Lyokoï (Discutons) 8 mars 2018 à 10:49 (UTC)
Les données lexicographiques arrivent sur Wikidata
Bonjour,
je sais qu’un certain nombre d’entre vous sont très dubitatifs quant à la gestion des données lexicographiques sur Wikidata (voir cette discussion). Cela étant dit, je poste ici l’information comme quoi Wikidata va commencer à prendre ce genre de nouvelles données en avril 2018, aucune date précise n’a été donnée pour le moment. L’annonce de ce message est disponible ici (en anglais). En résumé, tout ne sera pas pleinement fonctionnel dès le début et des fonctionnalités déjà prévues seront ajouter en cours de route tandis que des ajustements pourront également avoir lieu suivant comment les Wikidatiens s’emparent de ce nouveau projet. Il est demandé pour le moment de ne pas faire d’import automatisé et donc d’uniquement contribuer manuellement afin d’une part de voir comment les nouvelles données se structurent et d’autre part afin d’éviter toute violation de licence ; le message de Lea Lacroix (WMDE) se voulant apaisant sur ce sujet.
Je retiens surtout la phrase Senses will not be included in the first version (les sens ne seront pas inclus dans la première version), ce qui semble indiquer que l’idée est de les ajouter dans une autre version, ce qui semble contredire l’opinion de Vigneron (à moins que je l’ai mal comprise). Bien sûr, on peut inclure un sens sans inclure de définition, mais à quoi ça peut servir ? A détecter des synonymes, ou des équivalences de sens permettant de traduire un mot entre deux langues quelconques même si personne ne connait les deux langues à la fois ? Si c’est ça, cela ne peut pas marcher. Lmaltier (discussion) 7 mars 2018 à 18:23 (UTC)
Je vois dans le modèle de données : The senses are given as natural language definitions or glosses (les sens sont donnés sous forme de définitions en langue naturelle), ce qui contredit clairement Vigneron qui nous rassurait à ce sujet, Vigneron pour qui les définitions n’avaient pas à être incluses dans un tel projet : l’idée est bien d’inclure des définitions, et que ces définitions existent dans une version par langue (on peut avoir une définition du mot français définition écrite en tchétchène, une autre en tahitien, etc. Cela me rappelle OmegaWiki, et ça confirme toutes mes craintes. Lmaltier (discussion) 7 mars 2018 à 18:37 (UTC)
@Lmaltier : d’où as-tu extrait cette phrase dans la deuxième partie de ton message ? Au passage je ping VIGNERON pour le prévenir qu’on fait référence à certains de ses écrits. Pamputt7 mars 2018 à 18:40 (UTC)
J’avais seulement lu le texte, je n’avais pas regardé le schéma à droite de cette page, mais je vois maintenant que, techniquement, toutes les explications des wiktionnaires pourraient sans doute être importées un jour sur Wikidata via les "statements" (si on oublie les problèmes juridiques). Lmaltier (discussion) 7 mars 2018 à 18:59 (UTC)
Même si le projet est développé depuis plusieurs années, la première version déployée est forcément une beta qui ne contient par définition pas toutes les fonctionnalités. Par nature (d’autant plus pour un wiki), on ne sait pas exactement que les versions futures contiendront précisément et rien ne dit que les versions suivantes contiendront des gloses (personnellement, je n’en vois toujours pas l’intérêt ; pour l’anecdote, en 2012 Wikidata une « phase 3 » pour intégrer les requêtes directement dans l’interface était prévue, pas mal de gens l’attendait mais elle n’a finalement jamais vu le jour, le besoin a été résolu autrement notamment avec SPARQL qui est bien plus puissant que ce qui était prévu originellement), de plus une glose n’est pas vraiment une définition. Par exemple en me basant sur les exemples données précédemment (dont le modèle donné en lien ci-dessus), pour l’entrée chien, les gloses seraient juste un mot : 1. animal 2. personne, 3. prostitué, etc. (et même là, je ne vois toujours pas l’intérêt de ces gloses, le but évoqué est de faire la distinction entre les sens mais il y a déjà les autres propriétés pour cela, par exemple les synonymes ou les traductions qui ne peuvent effectivement pas être détectés et qui doivent donc forcément être stockés). De toute façon, structurellement, la présence ou l’absence des sens ne change pas grand’chose : soit on crée un élément avec deux sens L123-S1 (pour chien-animal) et L123-S2 (pour chien-personne), soit on crée deux éléments distincts : L123 (chien-animal) et L124 (chien-personne), dans tout les cas on peut stocker les mêmes informations (c’est juste la manière de stocker les données qui change). La première version permettra justement de déterminer la façon de faire (et d’ici là, il y a déjà eu plusieurs discussion ou l’on semble plutôt s’orienter sur une multiplication d’éléments plutôt que de sens ; par exemple tour serait réparti sur plusieurs éléments, car les homographes sont plus simples à gérer séparément ; idem pour le russe ou le breton où les formes et les sens ont tendance à se collisionner et où la séparation apporte plus de clarté, donc si on doit le faire pour certains cas, autant le faire tout le temps). Enfin, je suis un simple membre de la communauté wikimédienne comme vous, devant un futur projet (avec forcément une part d'incertitude), je ne détiens pas la vérité absolue (et mon avis personnel n’est que cela, si la communauté a un avis différent, je le suivrais). Cdlt, VIGNERON * discut.7 mars 2018 à 20:09 (UTC)
Il y a malentendu : je cite la page : A sense's gloss gives a natural definition of the sense. C’est fondamental, car ça conditionne le succès du projet, et tu as le droit de défendre ton opinion vis-à-vis des autres si elle te semble importante (et elle est plus qu’importante). Comme c’est parti, je ne vois que deux alternatives : des imports en masse avec des violations de licences, puis une fermeture du projet pour cette raison, ou une fermeture à terme par manque de contributeurs (comme sur OmegaWiki). Beaucoup de gens s’intéressent à l’aspect technique, mais il n’en restera pas beaucoup pour contribuer en rédigeant des définitions là-bas. Lmaltier (discussion) 8 mars 2018 à 06:57 (UTC)
C’est beau les gloses… Tu peux me donner celles que vous envisagez pour érodibilité, théosophie, tenir et être par exemple ? Je suis bien curieux de voir comment vous aller pouvoir décrire ces notions avec un seul mot, voire deux maximum… --— Lyokoï (Discutons) 8 mars 2018 à 10:21 (UTC)
Dans le cas putatif où les gloses serait jamais un jour intégrées, elles ne seraient sans doute pas descriptives (et les L ne portent pas sur des notions, on a déjà les Q pour cela ; la question de comment « décrire ces notions » est donc doublement mal posée) mais distinctives et seraient là pour distinguer plusieurs sens d’un lexeme. Donc déjà, si il n’y a qu’un sens, de quoi faudrait-il le distinguer ? Ceci dit, étant de bonne humeur, je tente l’exercice : érodibilité = capacité ; théosophie = 1. religions 2. doctrine ; tenir = les définitions de la plupart des sens sont déjà en un mot sur le Wiktionnaire ; être = même remarque. Cela me semble trivial, cela répond-il à ta curiosité ? Cdlt, VIGNERON * discut.8 mars 2018 à 13:00 (UTC)
Malheureusement, la page de description du modèle de données parle de définitions écrites en langue naturelle, ce qui est très, très différent. Et c’est cette page du modèle de données qui est utilisée comme référence. Je suggérerais de modifier cette page pour la mettre en conformité avec ce qui est expliqué ici, ça clarifierait les choses, car ça obligerait ceux qui ne sont pas d’accord avec ça à en discuter sérieusement. Lmaltier (discussion) 10 mars 2018 à 13:14 (UTC)
Moi je sais mais je ne participe pas à Wikidata ッ Sinon, où se trouve le lexique interne où l'on emploie glose au sens d'hyperonyme ? Parce que ce mot dénote et connote philologie ancienne, religion, en langue normale. Delarouvraie🌿8 mars 2018 à 10:55 (UTC)
Le modèle de données (qui n’est qu’une proposition générale faite il y a plus d'un an) peut faire office de lexique et lie explicitement vers w:glose (qui correspond à la deuxième acception de glose), à aucun moment il n’est question d’hyperonyme (ou plutôt la glose peut être un hyperonyme puisque c’est une façon simple et suffisante pour annoter brièvement mais cela peut tout autant ne pas être un hyperonyme ; et de toute façon, au moins dans un premier temps, il n’y aura pas de glose, la question ne se pose pas pour le moment). Cdlt, VIGNERON * discut.8 mars 2018 à 13:00 (UTC)
Argumenter à partir d’une idée personnelle, apparemment contraire à l’idée décrite dans la page du modèle de données du projet (qui semble elle-même contradictoire avec la référence qu'elle donne sur les gloses, c’est vrai), je pense que ça ne peux qu’entraîner de la confusion (même si c’est vrai que tout peut encore bouger)… Il faudrait vraiment discuter de ça sérieusement sur Wikidata pour que les choses deviennent enfin claires. Lmaltier (discussion) 9 mars 2018 à 06:47 (UTC)
Euh, en l’occurrence, ce message n’est pas mon idée personnelle, ni le modèle de données ni l’annonce de Léa ne sont de moi. Ceci dit, oui, mille fois oui, pour en discuter. Cdlt, VIGNERON * discut.9 mars 2018 à 07:08 (UTC)
Je suis très content, on va enfin voir si j’ai été tout ce temps un oiseau de mauvais augure, ou si je soulevais vraiment des problèmes compliqués à gérer. Par contre, je trouve que la ligne de démarcation entre ce qui est sous licence CC BY-SA et ce qui ne l’est pas, et peut donc être aspiré vers Wikidata sans mal, cette ligne n’est toujours pas clairement tracée. J’ai posé de nombreuses questions et toutes n’ont pas encore trouvées de réponse. Je trouve cela un peu ennuyeux Noé7 mars 2018 à 21:07 (UTC)
Bonjour, je relaie ici le message de BamLifa qui a été posté sur le bistro de Wikipédia du jour. Certains d’entre vous auront peut-être plus d’informations que la réponse donnée pour le moment par Ypirétis. Pamputt7 mars 2018 à 18:36 (UTC)
Bonsoir!
Je cherche le wikitionnaire fr-en au format StarDict. Quelau'un peut il m'indiquer comment se le procurer? BamLifa (discuter) 7 mars 2018 à 16:53 (CET)
Bonjour, est-ce que certains d’entre vous sont au courant de l’existence d’une page similaire à cette page du Wiktionnaire anglophone ici ? Si non, pensez-vous que ça ait un intérêt qu’on ait une telle page et si oui avec quel contenu (celui du Wiktionnaire anglophone ou un autre) ? Pamputt8 mars 2018 à 06:57 (UTC)
Bonjour. Les verbes pronominaux en breton se construisent avec en em comme en em dennañ. Si quelqu'un sait comment faire, serait-il possible de les considérer comme des verbes et non comme des locutions verbales pour le titre de section et la catégorisation ? Merci. --Yun(causer)8 mars 2018 à 15:01 (UTC)
Si je comprends bien, il suffit d’ajouter un peu de code dans Module:locution pour dire que tout ce qui commence et uniquement ce qui commence par Special:Index/en em est un verbe pronominal en breton (même si il n'y a que en em dennañ pour le moment).
@Darkdadaah et @Pamputt : sauf erreur, il suffit de reprendre et d’adapter les lignes 49 et suivantes, non ? (je ne suis pas spécialiste du Lua, je préfère vous laisser faire)
Oui, VIGNERON. Je ne savais pas où ça se passait mais le test à faire est bien celui que tu décris. En em dennañ était un premier essai. --Yun(causer)8 mars 2018 à 17:16 (UTC)
Bonjour à tous !! Je viens de faire un petit test sympathique sur ma chaîne YouTube après quelques réglages sur un logiciel de streaming (tout ça est d’une simplicité incroyable…) et je vous annonce que je serait en direct live (et mondovision, oui oui) à 22h30 : ici. Si vous avez un compte YouTube on pourra tchatter en direct avec tout le monde et j’enregistrerai de mon côté afin d’avoir la meilleure qualité d’encodage (le stream youtube descend en qualité de temps en temps) pour la version en ligne de la vidéo. À tout à l'heure j’espère ! --— Lyokoï (Discutons) 8 mars 2018 à 19:37 (UTC)
Salut Lyokoï, je ne suis pas sûr de pouvoir y assister donc amusez vous bien si je ne suis pas avec vous. En passant, pourquoi la licence indiquée est « Licence YouTube standard » ; tu peux mettre ça en CC by-sa ? Pamputt8 mars 2018 à 20:39 (UTC)
Ahah, c’est rigolo que tu fasses ça ce soir ! Du coup, bon anniversaire Lyokoï ! Et comme ton anniversaire tombe la journée internationale des femmes au travail, tu prévois d’améliorer des pages concernant des métiers pratiqués par des femmes ? Noé8 mars 2018 à 20:46 (UTC)
@Noé : Merci ! Aussi, oui. Je vais faire une petite heure de contribution, et si je vais partir sur malaisant (touchez-y pas avant le live SVP, ce serait gentil ! :D) je ne vais sûrement pas y rester tout le temps, je pense. Surtout s'il y a des propositions sympas sur le chat ! ^^ --— Lyokoï (Discutons) 8 mars 2018 à 21:26 (UTC)
Au final, c’était un super live ! Maintenant que j’ai un peu le logiciel en main, je vais pouvoir faire rapidement mes tutos de contribution au Wiktionnaire et les uploader partout. D’ailleurs j'ai une question, à quel rythme voulez-vous voir ce genre de live ? --— Lyokoï (Discutons) 8 mars 2018 à 23:04 (UTC)
Flute, je ne vois le message que maintenant. Dommage, ça m’aurait intéressé de participer. La prochaine fois je veux bien être notifier au moins un jour avant. :) De ce que je comprend la vidéo en question n’est pas encore en ligne, ou est-ce que je me fourvoie ? Bon post-anniversaire au passage ;) --Psychoslave (discussion) 9 mars 2018 à 07:40 (UTC)
Je mettrais la vidéo du live d’ici samedi. J'ai un tout petit peu de montage à faire (une coupure à boucher) ce soir et j’envoie l’upload. Vu que c’était un test surtout de la technique, j'ai pas trop fait de barouf, mais pour les prochaines fois, l'annonce sera plus importante. En tout cas, le logiciel de streaming OBS est vraiment simple à prendre en main (j'ai vu un tuto de 20 minutes et c’était plié) et la config de YouTube assez claire. Autres gros avantage d’OBS, c’est qu’on peut très facilement enregistrer une session chez soi et l’envoyer ensuite sans soucis. Je ferais mes tutos Wiktionnaire comme ça d’ici peu. Manque plus que je me liste les vidéos et leur contenu. --— Lyokoï (Discutons) 9 mars 2018 à 13:23 (UTC)
Atelier contributif, mardi 20 mars, 17h-19h, à la bibliothèque du 6e arrondissement, pour fêter la journée mondiale de la francophonie, avec donc un focus sur dix mots francophones.
C’est ouvert au grand public, alors n’hésitez pas à en parler à vos connaissances lyonnaises. Et sinon, préparez-vous à voir passer quelques contributions anonymes à ces dates là Noé10 mars 2018 à 15:48 (UTC)
Bon, on est assez à l’arrache, mais je vous mets déjà la version préliminaire des diapositives que nous utiliserons comme support pour l’atelier du 15 mars. Il manque encore la partie de Lyokoï, c’est à dire le guide pour ajouter des définitions, des mots liés et des étymologies. Pas la peine de commenter cette partie là, donc. Une partie des diapos proviennent de la présentation longue que nous avons déjà présenté ici en janvier. Vous pouvez nous faire part de toutes les critiques que vous voulez, et nous tâcherons d’améliorer ce document progressivement, de manière à ce qu’il soit réutilisable dans d’autres cadres, par n’importe qui Noé14 mars 2018 à 15:43 (UTC)
P. 2 Très sympa comme fil conducteur ! Pour continuer dans le code couleurs, essayer #7ca559 pour les synonymes, voir si ça donne quelque chose.
P. 5 Sa compréhension pour tout public > par tout public. Alentours sans s.
P. 10 C’est partis > C'est parti.
Fini ici.
Pour une prochaine fois
Je ne mettrais pas de point après les items des listes à puce (sauf après etc.), c'est plus dynamique sans point.
J'ai essayé une version plus flashy de la photo, mais ça impliquerait de refaire tous les bandeaux. C'est ici. Là, c'est vraiment une question de goût.
Merci pour tes retours ! J’ai un peu modifié le code couleur, mais je n’ai pas mis le vert pour les synonymes, parce qu’il renvoie au sol, et je voulais garder cette couleur pour les pages d’aide et de convention, parce que symboliquement, c’est le sol sur lequel on construit. Pour la saturation des couleurs, je préfère rester avec l’image originale, mais là c’est vraiment une affaire de goût, comme tu le dis. En fait, pour les synonymes, l’idéal aurait été la partie avec le filet de singe en plein milieu, mais ça tassait trop le reste. J’ai suivis les autres changements que tu indiquais. Je mettrai le fichier à jour lorsque j’aurai reçu les ajouts de Lyokoï Noé14 mars 2018 à 19:55 (UTC)
Retour d’expérience
Bonsoir,
Nous avons été jusqu’à dix personnes dans la pièce, grâce à l’aide des copains wikimédiens/wikipédiens. Il y avait en fait trois femmes venues exprès pour découvrir le Wiktionnaire, et nous pouvions bien les accompagner avec Lyokoï et Ltrlg ! La première partie d’introduction à pris 20 minutes environ, et ensuite nos trois participantes ont recherché des mots dans les livres mis à disposition par nos soins. Cedalyon, qui anime d’habitude les ateliers Wikipédia mensuels au même endroit, papillonnait autour, créant quelques entrées dans le Wiktionnaire, et essayant les astuces que nous montrions avec l’éditeur visuel. Les mots explorés et améliorés furent : fenotte, tarasque et Kwango. D’abord pour ajouter une attestation d’usage, puis une image, revoir ensuite les définitions (parfois en changeant de mot) et ajouter quelques synonymes. Nous avions prévus quelques diapos pour l’étymologie mais nous n’avons pas eu le temps de les laisser pratiquer.
La prochaine fois nous mettrons plutôt l’ajout de traduction comme cinquième mini-atelier. En tout cas le format a très bien fonctionné ! C’était pratique d’être beaucoup pour encadrer, mais c’était surtout dynamique d’aborder de nouveaux concepts (mise en forme, liens, modèles) en ajoutant rapidement de nouveaux contenus. La prochaine fois, il serait peut-être encore mieux de commencer par les illustrations, car cela ne demande vraiment pas de code, tandis que les attestations demandent déjà un peu d’italique et de gras ainsi que le modèle {{source}} dans lequel il faut être vigilant à mettre de l’italique et éventuellement des guillemets français qui peuvent être compliqués à saisir. Le positif d’avoir les images en second, c’est que les personnes qui apprennent sont plus concentrées au début, puis respirent un peu avec un truc plus simple avant d’attaquer la partie un peu plus compliquée sur les définitions. À voir.
En tout cas, les premières étapes ne nécessitaient pas de passer par le code, et ce fut bien apprécié de nos participantes. L’ajout d’image est ce qui les a le plus surprises, car en trois minutes c’était plié et avec de super images. D’arriver aux définitions au milieu du temps d’atelier ne leur a pas paru trop bizarre, et c’était l’occasion de refaire quelques explications techniques sur les mots et les difficultés à les définir. Avec cet atelier, on est assez dépendant des mots modifiés, mais ça permet de vraiment contribuer et de voir les pages s’améliorer petit à petit par touches successives. C’était assez chouette, j’ai trouvé. N’hésitez pas à réutiliser les diapos ! Si vous voulez les modifier, envoyez moi un petit courriel et je vous transmets la version modifiable du document. Si vous êtes intéressés pour l’enrichir avec d’autres parties, n’hésitez pas à me dire aussi ! Ce serait génial d’en faire un document modulable, dans lequel on puisse piocher selon les intérêts des gens et selon le temps dont on dispose, pour pouvoir animer plus facilement des ateliers, même sans être super-spécialistes du Wiktionnaire Noé15 mars 2018 à 23:29 (UTC)
Doublets étymologiques
Pour faire suite à cette discussion, je vous annonce que j'ai créé, il y a quelque temps déjà, un appendice sur les doublets en français (sur le wiktionnaire anglais).
Il n'est clairement pas abouti (certaines sections sont encore très brouillonnes), mais je pense qu'il offre déjà un bel aperçu du phénomène.
C’est vraiment du beau travail. La quantité d’information est assez importante. Mais j’y mettrai quelques bémols :
Les sources sont assez anciennes pour la plupart et ne prennent pas vraiment en compte les derniers avancement en étymologie.
Les doublets quasi-presque-qui y ressemble-mais qui ne sont pas des doublets c’est quand même très foireux… Parce qu’un mot latin donnent souvent plus qu’un doublet si on compte les autres mécanismes de dérivations (adjectivisation, emprunt, dénominalisation, passage par une langue régionale, etc.).
Certaines précisions sont un peu bancales… Rare au lieu de Jargon, Argot… Certains termes ne me semble pas appropriés.
Mais globalement, il n'y a que sur cette page que ce premier travail de regroupement des sources a été fait, et c’est un bon point de départ ! — Lyokoï (Discutons) 12 mars 2018 à 13:41 (UTC)
Remarques pertinentes :
Oui, je reconnais que cette section est foireuse. Mais paradoxalement, je trouve utile de mentionner explicitement ces cas-là, pour éviter qu'un enthousiaste ne les replace dans la liste authentique et ne la contamine.
Oui, à certains égards ça ressemble encore à une page personnelle. Je m'y permets certaines remarques et certaines formulations qui n'ont évidemment rien à faire dans une page communautaire ("Borrowings from Italian: Some of them are transparent, and thus uninteresting").
Pour les sources : celle de 1868 est obsolète, et je n'ai évidemment pas repris tout ce qui s'y trouvait. Je n'ai malheureusement pas accès à la thèse de 2015, qui n'est pas consultable en ligne. --Per utramque cavernam (discussion) 13 mars 2018 à 20:15 (UTC)
@Per utramque cavernam : Globalement, la page est quand même bonne, hein ! Par contre, je pense qu'il faut vraiment faire attention avec les étymologies. C’est toujours moins simple qu'on le croit. Et seule une analyse au cas par cas permettra d’en trouver des supplémentaires ou d’en éliminer. D’ailleurs, il faut aussi noter qu’un certains nombres de mot sont issus de langues d’oïl différentes et que donc le chemin traversé n’est pas identique, en cela le doublet n’en est presque jamais un pour peu que la même racine latine passe par une autre langue d’oïl et soit présente en langue régionale. Bref, chapeau pour ce qui a déjà été fait, j'ajouterai juste un disclaimer en début de page disant que la liste est à affiner et qu’elle peut être très différentes selon les considérations que l’on a des chemins étymologiques concernés. --— Lyokoï (Discutons) 16 mars 2018 à 18:50 (UTC)
WikiIndaba 2018
Présentation pour Wiki Indaba 2018.
Bonjour, Benoît Prieur et moi-même seront à Tunis du 16 au 18 mars prochain pour participer à la conférence WikiIndaba 2018. Cette conférence est une conférence des contributeurs aux projets Wikimedia du continent africain. Nous y serons pour y présenter le Wiktionnaire en espérant inciter certains (tous ?) participants à venir contribuer au Wiktionnaire dans des langues d’Afrique actuellement sous-représentées ici (arabe, berbère, peul, haoussa, swahili, …). Nous avons une présentation qui a été acceptée et un atelier de contribution également. L’idée de la présentation est d’essayer de montrer l’intérêt du Wiktionnaire (francophone) pour le développement et la visibilité des langues parlées en Afrique.
J’ai posté ci-contre une première version de la présentation que l’on compte donner. N’hésitez pas à me faire vos retours d’ici jeudi afin que je puisse en tenir compte. La forme est sûrement à améliorer (ce n’est pas ma spécialité). Autre information, on a 20-25 minutes de présentation au total donc on ne peut pas parler de tout. On ne sait pas encore si le speech sera en français, en anglais ou les deux ; ça dépendra de notre auditoire mais les dispositives sont en anglais. Je peux fournir le fichier odp si besoin. Pamputt10 mars 2018 à 23:30 (UTC)
Le contenu commence à prendre forme, c’est chouette. Il y a plusieurs tournures de phrases en anglais qui m’ont paru bizarre, notamment le titre qui ne nécessite pas de "The" initial il me semble, mais l’avis d’une personne maitrisant mieux la langue serait plus utile. En tout cas, je préférerai que vous changiez l’image de couverture, et que vous viriez mon nom, tant qu’à faire. Il y a déjà pas mal de versions différentes de cette présentation et celle-ci s’en éloigne fortement. Je préférerai que cet habillage reste associé à des présentations "tour d’horizon", dans lesquelles on explore tout le contenu. Et puis vous reprenez moins de dix pourcents de la présentation précédente, ça va, hein. Pour les crédits, il faudra que tu vois comment j’ai fais pour la présentation précédente, sinon le fichier risque de passer en procédure de suppression sur Commons. En gros, il faut ajouter des liens vers les fichiers présents dans les diapos, à l’aide d’un modèle. Et sinon, les chiffres que vous donnez sur la couverture des langues d’Afrique sont un peu étranges. Pour l’anglais notamment, vous donnez l’ensemble des entrées dans le projet anglophone là, non ? Ne vaudrait-il pas mieux restreindre à la définition de mots anglais ? Noé11 mars 2018 à 09:48 (UTC)
Très intéressant ; Deux remarques :
Le Bambara et le Songhaï ne sont pas dans la diapo des langues alors qu'ils sont plus fournis que le Wolof :/
J'ai bien compris que le but est d'encourager ceux qui ne connaissent pas mais je pense qu'une diapo sur les difficultés à prévoir permettrai de prévenir les éventuelles frustrations du débutant (Aide:Sommaire ?)
bon courage ! — message non signé de Rgaudin (d · c)
Bonsoir Noé et Rgaudin. Merci pour vos retours. Je viens d’envoyer une version remodelée qui essaie de tenir compte de vos remarques. Concernant la diapo 11, je ne l’ai pas modifiée (pour le moment) car cette diapo fait suite à la diapo 10 qui indique qu’il existe une version du Wiktionnaire dans chaque langue. La diapo 11 fait donc l’inventaire de l’avancement des Wiktionnaires dans les différentes langues parlées en Afrique. Le comptage inclut donc toutes les pages présentes dans chaque version linguistique. Cela explique donc pourquoi je ne parle pas du bambara ou du songhaï mais uniquement du wolof car le Wiktionnaire en bambara n’est malheureusement plus actif et celui en songhaï n’a semble-t-il jamais existé. Les chiffres pour ces langues sur le Wiktionnaire francophone sont donnés sur la diapo 15. Pour les images, j’ai rajouté les modèles adéquats sur la page Commons. Enfin pour l’anglais, -sche sur le Wiktionnaire anglophone m’a fait quelques corrections.
Concernant les difficultés, j’ai hésité à en parler ici car j’ai peur de manquer de temps lors de la présentation. Ce que j’avais en tête c’était : le manque d’accès à des ordinateurs connectés à internet ce qui implique une contribution par mobile (le Wiktionnaire ne doit pas être très adapté pour cela) ; l’absence ou la non-utilisation d'une orthographe standardisée pour certaines langues ; la relative difficulté d’apprentissage du wikicode du Wiktionnaire du fait de ses nombreux modèles ; … Donc j’envisage de traiter ces questions lors de l’atelier si elles surgissent dans la mesure où l’on aura un peu plus de temps.
Chouette. Bon choix pour l’image de couverture :) tu peux peut-être mettre une esperluette entre vos deux noms. Sinon trois petites remarques :
p3 : minority langages -> languages (et tu peux zapper minority)
p6 : enlever la majuscule en milieu de phrase.
p17 : je ne suis pas sûr qu'un chaton soit l'image la plus adaptée culturellement à l'endroit où vous ferez la présentation.
Pour les difficultés, celles mentionnées dans l’article sur le dico du mois sont également assez pertinente pour le Wiktionnaire. Un autre problème va être pour certaines langues d’avoir des attestations d’usage sous forme écrite. Il faudra peut-être enregistrer aussi des récits oraux pour ensuite en prélever des fragments afin d’avoir des attestations d’usage, ce qui prend bien plus de temps Noé12 mars 2018 à 23:23 (UTC)
J’ai uploadé une nouvelle version qui tient compte des remarques précédentes. J’ai ajouté un slide (en réserve) sur les difficultés potentielles, au cas où l’on a du temps ou des questions sur le sujet. J’ai aussi ajouté des points de contact pour le Wiktionnaire francophone (moi) et anglophone (Metaknowledge). Pamputt14 mars 2018 à 10:21 (UTC)
J'ai quelques modifs. Cela dit, je ne suis pas anglophone non plus.
P. 6 Mettre des guillemets anglais.
P. 7 Je n'aurais pas mis les to.
P. 9 Integrations sourced : suggestion de remplacement : information coming from.
P. 12 Remplacer deepen par improve.
P. 13 Pas de virgule avant les points de suspension. Ici et p. 15, 16, 24.
Merci Delarouvraie, j’ai pris en compte la plupart de tes commentaires (pour l’anglais j’ai préféré ne pas corriger car les anglophones ne me l’ont pas fait corriger ). Pamputt15 mars 2018 à 06:36 (UTC)
Compte-rendu
Voici un rapide compte-rendu de la conférence Wiki Indaba qui est en train de se terminer. On a fait un compte-rendu un peu plus fouilli ici. En ce qui concerne le Wiktionnaire, la présentation qu’on avait préparé n’a pas duré 20-25 minutes mais 7 minutes au final du fait d’un changement de programme. J’ai donc retiré pas mal de diapos et centré la présentation sur seulement quelques points. Ca a au moins permis de rencontrer des personnes impliqué dans l’ajout de mot en chaoui sur le Wiktionnaire francophone, à savoir Reda Kerbouche.
Lors de l’atelier que l’on a animé avec Benoît, on a eu une dizaine de personne dont seulement 2 francophones. Le fait d’être 2 a permis de présenter les gadgets « Ajout Trad » (sur les Wiktionnaires francophone et anglophone) et « CreerTrad » (pour le Wiktionnaire francophone). On a donné le contact de Metaknowledge pour le Wiktionnaire anglophone.
Mah3110 est un contributeur béninois qui vit sur Paris. J’aurais l’occasion de le revoir et on essaiera d’organiser des contributions ou formations autour du Wiktionnaire.
L’atelier en lui-même n’a pas permis de toucher un grand nombre de francophones mais les discussions en dehors des présentations ont été extrêmement riches. Reda Kerbouche est intéressé pour travailler à la création d'un WikiMOOC sur le Wiktionnaire. Il connait une équipe de vidéaste professionnel qui peut aider à cela. Ils ont par exemple réalisé des vidéo très pro sur un WikiMOOC en arabe.
Un petit groupe (dont Reda benkhadra) a ouvert un projet de Wikitionnaire en arabe marocain sur l’incubateur. Ils ont besoin d’aide technique pour l’import de modèle et module de base afin de disposer de la structure de base pour l’organisation de leur Wiktionnaire. Ils sont intéressés pour utiliser la même architecture que le Wiktionnaire francophone.
Uzoma Ozurumba, anglophone a ouvert un Wiktionnaire en igbo sur l’incubateur. Ce sont plutôt les anglophones qui peuvent lui apporter du soutien mais l’arrivée de Lingua Libre devra lui être présentée pour enregistrer des prononciations en igbo. Elle est très motivée pour promouvoir l’igbo.
On a aussi rencontré Modjou, contributrice en Côte d’Ivoire, qui est intéressée pour ajouter du contenu sur le français de Côte d’Ivoire et aussi potentiellement dans des langues parlées dans ce pays, tel que le baoulé.
Des contacts ont également été pris avec Anass Sedrati qui parle le rifain et l’arabe marocain et Ahmed Mohi El din qui parle l’arabe égyptien. Leurs contacts peuvent être donnés pour tester Lingua Libre sur l’écriture arabe. Et je les recontacterai pour qu’ils enregistrent des mots dans leur langue lors de la sortie de Lingua Libre.
En résumé, les discussions ont été super intéressantes et méritaient un déplacement sur le terrain. On a découvert un grand nombre de personnes intéressées par la thématique de la préservation et la diffusion des langues qu’ils parlent. Il faut maintenant essayer de leur apporter du soutien à distance pour une plus grande diversité linguistique sur les projets Wiktionnaire. Pamputt18 mars 2018 à 13:58 (UTC)
Merci pour ce compte-rendu ! Vous avez l’air d’avoir fait de bien belles rencontres, c’est super ! Pour le soutien technique aux nouveaux Wiktionnaire dans l’incubateur, je passe mon tour, ce n’est vraiment pas ma spécialité. Par contre, pour le WikiMOOC, c’est un projet d’ampleur et je pense que la réalisation de vidéo sera la bienvenue, mais que ce n’est pas forcément la première étape. Je pense qu’il nous faut d’abord poursuivre la rédaction des pages d’aide (notamment sur les illustrations, qui est en cours) et les visites guidées, dans le projet Tutoriels. Ensuite nous pourrons imaginer des formats filmés ainsi qu’un accompagnement par la communauté. Pour les vidéos, Lyokoï est super motivé aussi, et pour l’accompagnement des apprenants, je pense que nous avons encore bien du chemin à parcourir. Nous n’avons par exemple pas de Wiktionnaire:Forum des nouveaux (au moment où j’écris ces lignes le lien est rouge) qui permette aux débutants et débutantes de poser leurs questions. Et puis, de nombreuses pages de conventions et d’aide sont encore à améliorer, voir à créer, pour pouvoir orienter au mieux les personnes qui auraient besoin d’aide. C’est un projet au long cours, et les apports de différentes natures peuvent se nourrir les uns les autres. Les diapos pour des ateliers vont pouvoir nourrir les tutoriels par exemple, et des vidéos de contribution en direct pourront nourrir aussi la rédaction de pages d’aide. Du coup, toute aide est la bienvenue, et plus nous serons de personnes à s’intéresser à cela, mieux ce sera Noé19 mars 2018 à 09:55 (UTC)
Merci pour les précisions, effectivement, la formulation proposée est beaucoup plus claire. Où peut-on changer cela ? Jona (discussion) 14 mars 2018 à 08:10 (UTC)
Vocabulaire de la migration
Bonsoir,
Un projet est en cours autour du thème des migrations sur Wikidata, dans l’idée de définir une soixantaine de mots autour de ce sujet. Comme je ne vois pas trop pourquoi ce serait à Wikidata de définir des mots, je vous propose la liste ici ! L’intérêt, c’est qu’il y a plein de traductions à portée de main sur la page du projet sur Wikidata ! Noé11 mars 2018 à 23:15 (UTC)
Il semble que leur thème soit plutôt Migration non choisie. Des mots de l'expatriation heureuse sont absents. Il y en a plein, et le jour où on fera un thésaurus sur la Migration on pourra les donner. En revanche, je vois ici des mots hors sujet. N'est pas le Wix qui veut (hé hé). Delarouvraie🌿12 mars 2018 à 10:46 (UTC)
Alors, le téléphone arabe ayant fait son office, je me permets d’expliquer un peu plus ce projet. L’agence européenne Europeana dans le cadre du l’année européenne du patrimoine culturel 2018 propose de traduire une partie du thésaurus de l’Unesco autour la migration. L’idée c’est de traduire les libellés de 61 concepts dans (au moins) les 24 langues officielles de l’Union européenne pour que les 3500 institutions culturelles européennes membres d’Europeana disposent d'un vocabulaire plus fiables et cohérents. N'hésitez pas à participer si vous voulez et surtout n’hésiter pas à reprendre les labels de Wikidata (sans oublier que, vu qu'il n’y a pas encore de mots sur Wikidata, les libellés sont des traductions d’un concept et pas d’un mot). Cdlt, VIGNERON * discut.12 mars 2018 à 19:21 (UTC)
J'ai shooté balancé la prononciation /ki/ pour la première syllabe de chytridiomycose, en faisant confiance à mon feeling ressenti personnel de la prononciation du français, qui ne s'appuie sur aucune source, hormis ma maman maternelle (j'aime ma maman).
Aucune idée de l'étymologie de chytridio-, donc aucune justification pour la prononciation (mais ça vient du grec, c'est certain). Alors si l'une d'entre vous en sait plus, ce serait sympa d'améliorer chytridiomycose.
Je suis tombé sur une substantivation pour le mot hilare : « A l’opposé, pour l’hypocondre, le point d’équilibre sera a, mélancolie, et il faudra pour le faire rire un effort de même amplitude que pour amener l’hilare au désespoir ». Vu que c’est une utilisation impropre, est-ce qu’il faut le mettre ou pas dans le Wix ? Il n’y a apparemment pas de modèle ou de catégorie associée à ce genre d’utilisation.
Bonjour, avec Benoît Prieur nous sommes actuellement à WikiIndaba. Nous avons rencontré Mah3110, un Béninois qui avait créé « Signification des prénoms endogènes béninois » sur Wikipédia mais l’article s’est fait supprimé. J’ai demandé à le faire importer ici et il est maintenant disponible. N’hésitez pas à l’améliorer ou à sourcer ce qui peut l’être.
Par ailleurs, nous animerons un atelier de contributions au Wiktionnaire ce jour de 16h à 17h donc si vous êtes dans le coin à ce moment là, essayez d’accompagner les contributeurs du mieux possible (comme d’habitude quoi ). Pamputt17 mars 2018 à 08:28 (UTC)
Avec pamputt nous sommes donc allés à WikiIndaba et c'était super cool. Entre autres choses, on a fait des enregistrements de mots en ghomálá, bambara, baoulé, en rifain et en arabe marocain qui sont regroupés là pour le moment :
Par ailleurs on est en train de faire un petit compte-rendu pour WmFr qui nous paie les billets/hébergement dans lequel on parle beaucoup du wiktionnaire (en cours de rédaction) => .
Il est assez fastidieux à l'heure actuelle d'avoir la liste de toutes les événements (ateliers, conférences, etc) organisés par les wikimédiens. Pour améliorer cela, 0x010C (d · c · b) a développé un module Lua (Events calendar/about/fr). Fonctionnalités : multilingue, 2 mode d'affichage (calendrier ou liste ; le mode carte n'est pas terminé), possibilité de filtrer par ville et mots clés, export ical.
Le calendrier se trouve à différentes adresses sur meta : m:Wikimédia France/Actions#Calendrier, m:Template:Events calendar, etc. Et je vais demander la mise en place d'une redirection facile à communiquer. Quelque chose du genre agenda.wikipedia.fr et/ou agenda.wikimedia.fr
Pour profiter de toutes les fonctionnalités, il faut rajouter deux lignes dans votre common.js. Si le mouvement adopte cette solution, ces deux lignes de codes pourront être intégrées par défaut. Pyb (discussion) 18 mars 2018 à 19:50 (UTC)
@Lyokoï : Le fait que cet agenda soit sur meta a justement été pensé pour décentrer les pages d’événements qui existaient avant directement sur les projets (w:Wikipédia/Paris par exemple) ; cet agenda sur meta est bel et bien un agenda global au mouvement Wikimedia, il regroupe à la fois tous les projets (pas WP centré) et toutes les langues/pays (pas franco centré) tout en permettant à chacun de ne voir que ce qui l'intéresse.
Deux bons exemples :
la nouvelle page Events de l'Usergroup Wikisource qui affiche tous ce qui se rapporte à Wikisource, qu'importe la localisation des événements : meta:Wikisource Community User Group/Events ;
Samedi 17 mars, DaraDaraDara et moi sommes allé à une super journée de contribution à Genève (dans le cadre du mois de la contribution), qui proposait de s’intéresser à un quartier de la ville ainsi qu’à la manière d’intégrer des notations musicales dans les projets. Ce fut l’occasion de rencontrer ou revoir les collègues suisses, et c’était super chouette. La partie sur les notations musciales était assurée par Marco de Freitas qui a déjà rédigé un super guide pour Bien débuter avec la notation musicale dans wiki, permettant l’apprentissage du logiciel libre de notation musicale Lilypond. Pour expliquer très brièvement le principe, il s’agit de taper quelques lettres qui génèreront ensuite des lignes de partition musicale. Et ce système de codage est très bien intégré dans MediaWiki, et peut être saisi très facilement grâce à l’éditeur visuel ! Il suffit de cliquer sur Insérer > Notation musicale pour pouvoir écrire en lilypond, et l’affichage est mis à jour en direct. Au passage, si vous spécifiez italiano comme langage de notation, vous pouvez taper des notes avec le système do re mi, sinon, c’est le système anglo-germanique c d e.
Donc, on peut très facilement écrire des bouts de partition dans MediaWiki, mais ça sert à quoi ? Et bien, par exemple, sur Wikisource, vous pouvez trouver des livrets de chansons avec les partitions, telle que le chant des Canuts d’Aristide Bruant, et Lilypond génère même un fichier midi automatiquement pour l’écouter. Avec des extraits plus courts, nous pourrions illustrer dans le Wiktionnaire les pages concernant les notes et les intervalles. Sur Wikipédia il y a déjà quelques pages qui proposent des notations musicales ainsi. Avec DaraDaraDara, nous avons suivis le guide et avons expérimenté sur les pages octave, quinte et do. Pour octave par exemple, il suffit d’une petite ligne pour obtenir l’affichage suivant :
Que pensez-vous de l’ajout de ce type d’information dans le Wiktionnaire ? Seriez-vous favorable à ce que les notations musicales figurent sur les lignes d’exemples en dessous des définitions ? Enfin, si Lilypond vous intéresse, je vous invite à lire le guide, il est vraiment chouette, et vous pourrez obtenir sans mal de l’aide ensuite en sollicitant son rédacteur, DaraDaraDara ou moi Noé19 mars 2018 à 10:24 (UTC)
Si on en fait un modèle, ou si on l’intègre dans un modèle, ça ne sera plus géré en natif par MediaWiki, donc plus géré par l’éditeur visuel, et je pense que ce serait moins bien. Mais je suis d’accord que le code est pas super élégant Noé19 mars 2018 à 14:23 (UTC)
Désolé que tu ai passé du temps là-dessus. Il me semblait bien que ça allait être compliqué. Du coup, un petit bout de code, ça vous dérange ou j’peux ajouter des bouts de partitions un peu partout ? Noé23 mars 2018 à 18:10 (UTC)
20 mars : journée internationale de la francophonie
Diapositives pour animer un atelier à Lyon
Comme déjà annoncé un peu plus haut, Lyokoï, Pierre Tribhou et moi allons animer un atelier à Lyon à l’occasion de la journée internationale de la francophonie. Ce sera le 20 mars de 17h à 19h dans la bibliothèque municipale du sixième arrondissement de Lyon.
Pour l’occasion, j’ai amélioré les diapositives préparées la semaine dernière, en refaisant l’intro pour coller au thème du jour et en adaptant les captures d’écran pour qu’elles montrent des pages liées au thème, et permettent d’expliquer davantage de choses. Nous sommes partis dans l’idée de faire comme fil rouge un thésaurus sur la voix, alors merci de ne pas le commencer avant ! Nous amènerons les gens à contribuer sur les mots qu’ils préfèrent, dans le champ lexical de la voix, ou parmi les dix mots choisis cette année pour promouvoir la langue française. Les gens seront amenés à contribuer par quatre chemins successifs : ajout d’image, ajout d’une attestation d’usage, ajout de définition et ajout de synonymes et autres mots liés.
N’hésitez pas à faire des retours sur les diapos pour les améliorer, corriger des erreurs ou rendre plus compréhensible certaines parties. Ce matériel est bien évidemment mis sur Commons pour que vous puissiez le réutiliser de votre côté, avec ou sans nous. Si vous voulez les utiliser pour un autre évènement, n’hésitez pas à m’envoyer un courriel et je vous transmettrai la version modifiable pour que vous puissiez l’adapter à votre convenance Noé19 mars 2018 à 22:07 (UTC)
RAS. C'est clair. De mon côté, je cherche un document semblable pour une future présentation à des personnes peu à l'aise avec l'informatique. Si quelqu'un a ça ? Delarouvraie🌿20 mars 2018 à 13:44 (UTC)
Merci pour ton retour ! Nous n’avons pas encore eu à faire ça, mais nous pourrions adapter l’existant. Voudrais-tu plutôt présenter le contenu du Wiktionnaire ou amener les gens à contribuer ? Selon tes buts, tu pourrais plutôt reprendre les diapos de janvier ou celle-ci, à toi de voir. Je veux bien t’aider à préparer des diapos si tu veux Noé20 mars 2018 à 23:17 (UTC)
Retour d’expérience
C’était chouette. Nous avons accueilli une seule nouvelle personne, qui a surtout été suivie par Lyokoï, tandis que je montrais les quelques diapos préparées. C’est un peu décevant, alors que nous l’avions mis dans le calendrier du mois de la contribution et avions tenté de faire un peu de publicité autour de nous. A nos côtés, Ltrlg, Romainbehar et Pierre Tribhou ont pu contribuer, et ce fut donc tout autant un éditathon qu’un atelier. Nous avons papillonné autour des dix mots, et le bilan est consultable pour quelques jours sur la page Dis-moi dix mots (jusqu’à ce que la liste de suivis ce soit effacée) et sinon sur le Tableau de bord de l’évènement. Oui, on a essayé ce petit outil développé par la Fondation Wikimédia qui sert à faire des bilans de ce genre de rencontres. Il calcule et permet d’afficher la liste des contributions faites par les personnes inscrites durant la durée de l’évènement. Bon, c’est rien de fou, mais ça permet d’avoir quelques chiffres. J’sais pas si j’suis totalement convaincu que ça serve à quelque chose, mais bon, c’était la première fois et j’voulais voir si ça fonctionnait bien avec le Wiktionnaire. C’est pas trop mal sauf que ça ne compte pas les modifications faites dans l’espace de nom Thésaurus, et je leur ai fais un retour pour leur signaler Noé20 mars 2018 à 23:17 (UTC)
Yo ! J'ai formé une mamie qui était très curieuse et surtout très volontaire pour montrer à ses petits enfants qu’elle aussi pouvait faire de l’internet ! D’ailleurs, elle est repartie avec une version imprimée de la page mémérer que nous avons modifié ensemble. Je pense que nous avons là un axe de réflexion pour l’intégration de nos ainés dans le projet. Eux qui sont très mal informatisé en général, pouvoir leur faire imprimer leur travaux en fin d’atelier pour qu’ils puissent partir avec une preuve de leurs efforts et avec un support de discussion avec leur famille, je pense que c’est quelque chose que nous devons creuser plus dans nos ateliers. J'ajouterai même surtout en bibliothèques car c’est là qu’on est le plus en contact avec ces personnes. Il serait intéressant de rencontrer le doyen de notre projet, Papypierre, à ce sujet afin que nous facilitions nos contacts avec cette tranche de la population.
Certes, le fait que nous ayons multiplié les publicités et que nous nous retrouvions qu’avec une seule personne, c’était très décevant… Et je pense que nous devons aller plus loin dans nos méthodes de communications (enfin, ce qu’il est possible de faire pour des bénévoles comme nous). L’association Wikimédia France a notamment un rôle à jouer là-dedans.
Ce soir j'ai fait un atelier "créer son blog" et il y avait 9 inscrits et 9 présents, avec beaucoup moins de communication... De mon point de vue, je dois évidemment répondre à la forte demande, mais c'est aussi important de créer la demande par l'offre. Je vais rappeler ceux qui s'étaient désinscrits, histoire d'avoir un peu plus d'infos pour le bilan. Mais vous avez été géniaux. Ah et il faut que j'importe les photos de l'atelier sur commons. --Pierre Tribhou (discussion) 27 mars 2018 à 20:10 (UTC)
Nom communs féminins/masculins
Je me demandais quel genre avait le plus de terme parmi les noms communs français. Nous avons bien , mais pas de sous-catégorie par genre. Ce serait peut-être quelque chose à ajouter, non ?
— message non signé de Psychoslave (d · c)
Par le biais des modèles, nous pourrions le faire sans même modifier les pages existantes (sauf que certains adjectifs contiennent encore {{m}}, {{f}} et {{mf}}).
Mais la dernière fois que cela avait été proposé, il n'y a pas eu de consensus clair. Du coup, une prise de décision s'imposerait. JackPotte ($♠) 20 mars 2018 à 16:18 (UTC)
Live anniversaire es 14 ans du Wiktionnaire ce 22 mars à 22h30 !!
Salut à tous ! Je vous annonce donc un live pour l’anniversaire du Wiktionnaire ce 22 mars au soir ! Je ferai tout pour être à l’heure à 22h30, mais c’est le bazar dans les transports et les Lyonnais boivent un coup juste avant (le destin est un peu contre moi…). J'ai deux-trois idées de sujet de contribution, mais je suis preneur de vos avis et envies pour cette session ! A bientôt ! --— Lyokoï (Discutons) 21 mars 2018 à 07:44 (UTC)
@Renard Migrant : si il y a conflit, il serait assez schizophrénique vu qu’une seule et même personne a ajouté l’image et le commentaire. @Urhixidur : pourrais-tu expliqué tes ajouts contradictoires ? (surtout que - sauf erreur - le cerf n’est pas vraiment éviré, les bois marquent clairement le sexe). Après, si on veut un cerf ramé et avec toute sa virilité, ce ne sont pas les illustrations qui manquent sur Commons, c’est très facile à trouver (File:Blason ville fr Chambon-sur-Lignon (HauteLoire).svg ou File:Coat of arms MacTavish of Gartbeg.svg par exemple, ce dernier utilisant une rencontre cela évite le problème de l’entrejambe). Cdlt, VIGNERON * discut.25 mars 2018 à 18:04 (UTC)
Il n’y a pas de contradiction, la note est factuelle. En héraldique continentale (par opposition à la britannique), les bêtes héraldiques incluent un vit par défaut. S’il est d’un autre émail, la bête est vilénée ; s’il est absent, elle est évirée. L’illustration ne correspond donc pas au blason. Urhixidur (discussion) 5 avril 2018 à 16:13 (UTC)
Quel est le sens principal de homme, « être humain de sexe masculin » ou « être de l’espèce humaine, mâle ou femelle » ?
Quelle est la meilleure image pour montrer chaque sens ?
Je suis peut-être trop influencé par le mouvement linguistique non-sexiste américain, et je ne peux peut-être pas juger l’acceptabilité de homme comme « être de l’espèce humaine, mâle ou femelle ».
Si vous comparez l’ancienne version, ma modification et la modification par Delarouvraie, vous trouverez qu’elle et moi ne sommes pas d’accord sur les images et l’ordre des sens.
Mon motif est comme suit :
le premier sens de homme est « être humain de sexe masculin » justement comme l’ancienne version ;
la première image de l’ancienne version n’a pas de contraste avec une femme et n’est donc pas claire entre les sens 1 et 2 ;
la deuxième image de l’ancienne version montre bien une femme, non pas un homme.
Je voudrais savoir si ou non la phrase suivante est étrange pour les locuteurs natifs :
Comme tous les mammifères, l’homme allaite ses petits. ()
C’est une traduction de la phrase fameuse anglaise man being a mammal breastfeeds his young par Casey Miller et Kate Swift en 1976 (→ voir man). Et les phrases suivantes sont-elles acceptables ?
Comme tous les mammifères, la femme allaite ses petits.
Comme tous les mammifères, l’être humain allaite ses petits.
Comme tous les mammifères, le cheval allaite ses petits.
Comme tous les mammifères, le bovin allaite ses petits.
Le motif de Delarouvraie est comme suit, si je le comprends bien :
le premier sens de homme est « être de l’espèce humaine, mâle ou femelle » ;
une image pour « être humain de sexe masculin » doit être assez anatomique (au moins nu) ;
Les phrases 1 et 2 paraissent bizarres, on emploierait plutôt la phrase 3. Du point de vue étymologique, on peut faire remonter le mot homme au latin homo, qui signifie être humain, sans distinction de sexe. Mais l’évolution de la langue a fait que les deux sens, bien différents, sont en concurrence, et que le sens utilisé en opposition à femme a plutôt pris le dessus dans beaucoup de contextes, c’est ce qui rend la phrase 1 bizarre. Ce qui rend la phrase 2 bizarre, c’est que le mot femme n’a pas le sens d’être humain en général. Lmaltier (discussion) 26 mars 2018 à 05:57 (UTC)
J'ai initié une discussion après une réversion sans explication. J'ai commencé par l'hyperonyme, l'espèce, puis le sens sens propre d'être sexué, et enfin les sens abstraits. C'est bien ainsi que fonctionne la langue et idéalement les dictionnaires.
Comme tous les mammifères, l’homme (sens 1) allaite ses petits : mais oui !
Parler de sexe sans user de langage sexué (sens 2) ???
Pour expliquer ce qu'est un homme (sens 2), on fait comme pour la page femme, on montre un individu avec son caractère sexuel principal ; sur cette page femme, le sens abstrait (≃ sens 3) est également illustré avec une deuxième image d'individue montrant son sexe sans que cela cause de crispation. Delarouvraie🌿26 mars 2018 à 06:57 (UTC)
Merci pour ce clair résumé de votre désaccord. Je ne saurai pas dire comment fonctionne la langue, mais aller du plus général au plus précis est la façon dont fonctionne un dictionnaire, oui. Je suis assez d’accord pour considérer que la première définition soit homme pour être humain. Quant à l’illustration, il me semble important de montrer que la différence entre mâle et femelle ne se base pas sur des traits secondaires mais bien sur des différences biologiques (organes sexuels, chromosomes et dosage hormonal). Comme il est difficile de montrer la différence chromosomique ou hormonale, il me paraît important de montrer la différence par un corps nu. Ce n’est pas la physionomie générale, la taille des hanches, des seins ou des cheveux qui différencient les mâles et les femelles. C’est, notamment, les organes génitaux extérieurs. Et la base d’images de Commons nous permet d’avoir des illustrations artistiques ou pédagogiques qui ne soient pas vulgaire, alors autant les utiliser Noé26 mars 2018 à 09:34 (UTC)
Il n’y a pas de règle selon laquelle l’hyperonyme soit placée devant l’hyponyme. Nous avons donc {{en particulier}} et {{par extension}}, et nous pouvons choisir l’un des deux ordres :
Il est étonnant que vous deux ne trouvez pas étrange la phrase l’homme allaite ses petits, mais bon, c’est votre jugement d’acceptabilité. On peut dire bien que c’est un chien en se référant à une chienne, mais on peut difficilement dire que c’est un homme en se référant à une femme. Le mot homme pour l’être humain doit être collectif ou indéfini, pas spécifique. Ça signifie que ce sens est plutôt une extension. — TAKASUGI Shinji (d) 26 mars 2018 à 10:29 (UTC)
Voir écrite cette phrase m’amène à penser qu’il manque une majuscule pour préciser plus finement qu’il s’agit de l’Homme en tant qu’espèce. Par contre à l’oral elle ne me pose aucun problème. Je ne prétends pas que tous les francophones auraient le même jugement pour autant. D’autres avis seraient les bienvenus Noé26 mars 2018 à 10:35 (UTC)
La page étant bloquée (c'est élégant) au moment où je veux ajouter cette citation, je la mets ici. Elle est pour l'actuel sens 1 (espèce).
* De nombreux caractères, comme l’allaitement, conduisent aux mêmes modèles de parentés chez l’homme, le poulet et l’ornithorynque que la myoglobine.— (Robert Boyd et Joan Silk, L'Aventure humaine : Des molécules à la culture, Paris, De Boeck Supérieur, 2003, p. 107).
Tous les dictionnaires que j'ai consulté mettent le sens d'humain en I et le sens de mâle en II. L'étymologie du TLFi note que le latin homo, hominem voulait d'abord dire humain puis a aussi pris le sens de mâle a « l'époque impériale » en supplantant vir. La séparation est donc ancienne et l'ordre des définitions ne fait pas de débat dans les dicos. — Dakdada26 mars 2018 à 14:30 (UTC)
Merci pour l’information. Mais n’est-ce pas que toutes les légendes suivantes ne sont pas également acceptables ?
A
B
A1. Une peinture de l’Homme A2. Une peinture d’un homme
B1. Une reconstruction de l’Homme B2. Une reconstruction d’un homme B3. Une reconstruction d’une femme
C
D
C1. Une photo de l’Homme C2. Une photo de deux hommes C3. Une photo d’un homme et une femme
D1. Une image de l’Homme D2. Une image de deux hommes D3. Une image d’un homme et une femme
Bien sûr. J’ai montré que le sens principal de homme est plutôt « être humain mâle » aujourd’hui, quelle que soit son étymologie. Dans le cas de chien, on peut dire clairement deux chiens pour un couple d’un chien mâle et d’une chienne, mais ce n’est pas le cas de homme : deux hommes, c’est toujours deux êtres humains mâles. Ce mot n’est donc pas neutre entre les deux sexes mais principalement mâle.
Cela dit, si la majorité des contributeurs préfère placer le sens d’« être humain » à la première ligne, je propose d’ajouter {{terme|collectif ou générique}} au début de la ligne et une note d’usage à la fin. Ce n’est jamais simplement « être humain ». — TAKASUGI Shinji (d) 27 mars 2018 à 04:03 (UTC)
je suis aussi pour qu'on mette être humain en première ligne, mais ta remarque est fort pertinente. Pour {{terme|collectif ou générique}}Hector (discussion) 27 mars 2018 à 07:51 (UTC)
Oui, le premier sens ne s'applique pas à des individus et est plus général et abstrait. Du coup les illustrations de personnes ne peuvent pas représenter ce sens (i.e. aucune des images et légendes ci-dessus ne marchent avec ce sens). Je ne suis même pas sûr qu'on puisse illustrer correctement cela. — Dakdada27 mars 2018 à 09:36 (UTC)
J’ai pourtant essayé. Je suis pourtant assez d’accord, mais je pense quand même qu’on peut appliquer le terme à des individus si c'est par opposition à animal. Lmaltier (discussion) 27 mars 2018 à 17:58 (UTC)
Le premier sens n'est pas abstrait, il est biologique. Trois projet d'illustrations pour ce sens d'individu de l'espèce humaine. J'ai déjà proposé le premier d'entre eux en compromis, mais il a sauté à cause du blocage.
Images alternatives pour le sens « individu de l'espèce humaine »
Une femelle et un mâle de l'espèce homme, image de compromis non retenue par TS
Squelette d’Ardi, considéré au début du XXI° siècle comme le plus ancien homme
Citations, en plus de celle que j'ai donnée plus haut sur l'allaitement :
Si l’on se situe dans l'histoire longue, le système alimentaire a profondément évolué depuis que l’homme est apparu sur Terre, il y a environ 2 millions d’années.— (Jean-Louis Rastoin et Gérard Ghersi, Le Système alimentaire mondial : Concepts et méthodes, analyses et dynamiques, Versailles, éditions Quae, 2010, p. 129).
Plus la pénétration de l’homme est forte, moins le milieu est « naturel ». Celui-ci ne l’est totalement que là où l’homme est absent. Au centre du milieu se trouve l’homme dont l’intelligence le transforme. La noosphère (de noos, l’intelligence) en fait partie intégrante. — (Thành Khôi Lê, L’Éducation, cultures et sociétés, Paris, publications de la Sorbonne, 1991, p. 149). Delarouvraie🌿27 mars 2018 à 13:15 (UTC)
Ce n’est pas un blocage mais la protection de la version avant ma modification (et avant ton annulation). « Abstrait » veut dire ici que l’Homme ne peut pas être spécifique (sens linguistique) : il ne se réfère pas à un individu distinct. Un « individu de l’espèce humaine », c’est soit un homme ou une femme, non pas l’Homme. L’évolution de l’Homme.D’ailleurs, comme les anthropologues appellent seulement le genre Homo l’Homme, Lucy est simplement inappropriée. Quant au sens plus commun de homme, l’article Homme sur Wikipédia explique bien l’homme par opposition à la femme, non pas l’être humain. — TAKASUGI Shinji (d) 27 mars 2018 à 14:33 (UTC)
Avant ta suppression de mes images et après ton blocage/protection/figement/arrêt de mes propositions de remplacement d'une de mes images et d'intégration de l'une des tiennes. Ah et puis, je croyais qu'un admin ne pouvait pas bloquer une page sur laquelle il est lui-même en conflit d'édition ? Qu'en pensent les autres admins ? Sur le fond, avant de convoquer les anthropologues, les linguistes et Wikipédia, analyse juste les trois exemples que j'ai donnés. Et il y en a des tonnes du même tonneau, mais ça va bien comme ça. Delarouvraie🌿27 mars 2018 à 14:57 (UTC)
Vu. Et c'est bien toi qui as supprimé mes images. Tu as mis cette discussion sur la Wikidémie et non sur la page dédiée ; je suppose que tu voulais des avis de tierces personnes ? Je te propose donc une chose, de les laisser parler et de nous engager l'un et l'autre à ne pas répondre ni ici ni ailleurs sur ce sujet. Disons jusqu'au premier avril. Cela te convient-il ? Delarouvraie🌿27 mars 2018 à 15:47 (UTC)
Je suis désolé pour cette mécommunication et désolé si tu es offensée. J’ai bien protégé la version de 2018-03-25T11:20:54, qui ne comprend pas ma modification, et je l’ai fait à 2018-03-25T23:11:48. — TAKASUGI Shinji (d) 28 mars 2018 à 02:08 (UTC)
Ce que j'en pense : d'abord il faut retravailler les définitions. Tous les dicos ont deux grandes catégories 1) être humain 2) humain mâle, dans cet ordre, avec toutes les autres définitions qui en découlent placées en sous-définition de l'un ou l'autre. On devrait donc repartir sur ces bases, notamment parce qu'il nous manque pas mal de définitions, ce qui pourrait expliquer en partie le contentieux ci-dessus.
Quant aux illustrations, elles ne devraient être utilisées que si elles éclaircissent la définition. Illustrer un sens abstrait, difficile à représenté, ou simplement mal défini, n'aidera pas les lecteurs. Pour le sens d'humain mâle, ce n'est pas trop difficile, mais pour le sens d'être humain, c'est plus difficile, car il y a différents sous-sens subtils et différents. Encore une fois donc, je recommande de travailler sur les définitions et de ne chercher des illustrations qu'après être arrivé à un résultat consensuel. — Dakdada27 mars 2018 à 16:04 (UTC)
C’est ce que j’ai essayé de commencer à faire, en mettant la définition être humain en premier, en précisant que ce sens est souvent utilisé par opposition à animal, et en mettant une illustration qui joue sur cette opposition (et qui montre que ce sens ne dépend ni du sexe ni de l’âge). C’est déjà mieux. Dites ce que vous en pensez. Lmaltier (discussion) 27 mars 2018 à 17:35 (UTC)
Merci à vous tous pour vos coopérations. Serait-il possible d’ajouter {{terme|collectif ou générique}} au début ? Et il serait mieux d’avoir une note d’usage indiquant qu’au contraire des autres noms d’espèce, homme ne peut pas se référer spécifiquement à une femelle de cette espèce : on dit femme dans ce cas. — TAKASUGI Shinji (d) 28 mars 2018 à 02:08 (UTC)
On peut mettre une note de ce genre, mais il faut vraiment bien travailler le texte pour éviter de dire quelque chose qui serait en général vrai mais parfois faux. Lmaltier (discussion) 28 mars 2018 à 05:47 (UTC)
Le sens être humain de sexe masculin ne s’applique en pratique que pour des adultes. Par exemple, on ne parle pas d’homme ou de femme pour des bébés. C’est pourquoi j’aurais tendance à le fusionner avec le sens 5. Qu’en pensez-vous ? Lmaltier (discussion) 28 mars 2018 à 05:44 (UTC)
Merci, mais j’étais bien certain que personne ne contesterait cette évidence. Ma question était plutôt : y aurait-il une raison quelconque pouvant conduire à ne pas fusionner les deux sens ? Lmaltier (discussion) 29 mars 2018 à 06:00 (UTC)
J'ai suivi la reco de Dakdada qui consistait à d'abord se mettre d'accord sur les définitions]]. Je le remercie. Je ne remercie pas l'administrateur qui a profité du blocage pour modifier la page. Je reprends donc certains de vos éléments et ceux que j'étais en train de mettre en place avant la suppression de facto de mes modifs. Je vois deux grands sens : un sens biologique et un sens social. À l'intérieur de chacun de ces sens, il y a la distinction : 1. sens collectif comprenant fm et 2. sens m. C'est l'ordre qui comprends le moins de redites. Delarouvraie🌿29 mars 2018 à 11:55 (UTC)
@Delarouvraie : : Lmaltier (discussion) 1 avril 2018 à 07:35 (UTC)
Je ne comprends pas la distinction un sens biologique et un sens social (en principe la biologie a toujours son mot à dire dans l’emploi du mot homme ; est-ce que la remarque serait par hasard liée aux personnes transgenre ?), ni sens collectif comprenant fm : le mot homme est toujours masculin, on ne dit jamais une homme. Par ailleurs, cette page est faite pour discuter. Si personne n’est en désaccord avec la proposition ci-dessus de fusion de sens, je vais la faire. Si quelqu’un a une objection, merci d’expliquer cette objection pour que la discussion puisse aboutir. Lmaltier (discussion) 30 mars 2018 à 16:35 (UTC)
Je viens de voir que la définition du sens utilisé en sciences, sur laquelle j’avais travaillé, a été changée. Qu’est-ce qui n’allait pas avec ma version ? En tout cas, je vois bien ce qui ne va pas avec la version actuelle : en sciences, le mot homme s’emploie pour diverses espèces du genre Homo, pas seulement Homo sapiens, même si l’usage pour parler des humains actuels ne concerne bien sûr que Homo sapiens. Lmaltier (discussion) 29 mars 2018 à 17:39 (UTC)
Peut-on utiliser le modèle:voir dans ces cas là ? Il y a d'ailleurs un livre qui rassemble des caractères assez proches et dont on peut s'inspirer : Synoptical Studies in Chinese Character de Herbert Allen Giles.
PS: J'viens de voir que ça avait déjà été utilisé, notamment ici : 日
Nous n’avons pas encore de règle. Jusqu’à maintenant, on utilise ce modèle généralement pour des variantes (d’autres glyphes du même sinogramme). Mais c’est probablement utile de montrer des caractères semblables. — TAKASUGI Shinji (d) 26 mars 2018 à 11:35 (UTC)
Il n’y a pas de critère de ressemblance. Par exemple, pour moi, 八 et 入 ne sont pas semblables (la séparation ou non, c’est une grande différence). Mais mieux que rien. — TAKASUGI Shinji (d) 26 mars 2018 à 16:16 (UTC)
Je ne suis pas sûr qu'il soit possible d'en définir. Certains ont un trait qui penche au lieu d'un trait plat : 干 / 千, 天 / 夭. Certains ont des traits qui dépassent différemment : 攵 / 夂 / 夊, 日 / 曰. D'autres ont la forme de certains traits qui changent 冃 / ⺼. Et puis, il y a ceux où il y a un trait de plus ou de moins 西 / 酉, 乌 / 鸟. Le Synoptical Studies in Chinese Character de Herbert Allen Giles est encore plus généreux en incluant des caractères qui diffèrent davantage mais qui peuvent être confondus : 蕭 / 簫, 東 / 柬, 哀 / 衷 / 衰 / 裒 / 袞 / 袁, 襄 / 囊. Assassas77 (discussion) 27 mars 2018 à 06:36 (UTC)
En principe non, on n’utilise pas le modèle voir dans ce genre de cas : c’est expliqué dans la documentation. Et c’est vrai que la ressemblance, c’est assez subjectif. Pour moi, il faut que l’alimentation des modèles voir puisse être automatisée, que ce soit objectif. Pourquoi ne pas plutôt utiliser la suite de la page, par exemple une section Notes, si on veut signaler des ressemblances pouvant induire en erreur les non-spécialistes, un peu comme on le fait pour les paronymes ? Lmaltier (discussion) 26 mars 2018 à 18:59 (UTC)
Nous ne pouvons pas utiliser la section de paronymes, parce qu’elle est placée dans la section de prononciation. En général on montre des variantes dans la ligne de « Forme alternative » de la section de caractère (p. ex. 边), mais il y a probablement beaucoup d’exceptions. Le modèle très compliqué {{Étymologie graphique chinoise}} est mantenu presque seulement par Micheletb. — TAKASUGI Shinji (d) 27 mars 2018 à 07:28 (UTC)
Est-ce que ça a du sens de parler d'homographe plutôt ? Ou de parographe ? Dans tous les cas, ça peut être un début. Aussi, je propose comme critère un truc comme :
Un changement sur un trait
L'orientation différente du caractère
La confusion notoire de deux caractères ou plus
Mais ce n'est qu'une proposition. Autant partir sur une base simple et objective (changement de seulement un trait) et à l'étendre ensuite si on constate que ce n'est pas suffisant. --— Lyokoï (Discutons) 28 mars 2018 à 13:19 (UTC)
Si j'ai bien compris les définitions données pour ces termes :
homographes : ce serait le cas de 長 qui peut se prononcer cháng (\ʈ͡ʂʰɑŋ³⁵\ l'adjectif « long ») ou zhǎng (\ʈ͡ʂɑŋ²¹⁴\ le verbe « grandir »)
parographes : il faut que ça vienne de deux langues différentes (?) donc le mot histoire, 历史 en chinois simplifié et 歴史 en japonais ou chinois traditionnel.
Je ne suis pas spécialiste de ces termes :D Après des petites recherches, ils appellent ça des « 形似字 » en chinois, des caractères de formes similaires. Assassas77 (discussion) 28 mars 2018 à 20:55 (UTC)
Les "formes alternatives" (paramètre "variante =" du modèle) sont des tracés différents pour le même caractère ; le tracé peut être très différent (par exemple pour les caractères simplifiés). Ce sont les caractères que l'on trouve (en principe) dans les dictionnaires de variante (http://dict.variants.moe.edu.tw/ est très complet).
Le "voir aussi" utilisé informellement (paramètre "rapprochement=" du modèle) peut être utilisé pour toutes sortes de raison, y compris une similitude graphique. Voir par exemple 夂 et l'utilisation de son paramètre "| rapprochement =".
Mais je n'ai pas noté ça systématiquement, et les paramètres du modèle ayant évolué certains sont restés sur d'ancienne version où cette distinction n'était pas faite.
Pragmatiquement, il vaut mieux indiquer les similitudes graphiques quand un lecteur non sinisant est susceptible de ne pas bien voir qu'il y a une différence ; l'idée est ici de faciliter l'étude du caractère pour un débutant - c'est très subjectif. En pratique, ces "détrompeurs" de similitudes correspondent souvent à des cas où je me suis moi-même fait piéger :D ...
Quel paramètre rapprochement ? Il n’y a pas de paramètre rapprochement documenté, ni rien de ce genre quand on regarde le code du modèle. Et on n’a de toute façon pas à ajouter des paramètres sans discussion. Il est d’ailleurs bien indiqué en gros dans le modèle de ne pas y toucher sans un consensus clair. Son utilisation était claire, il faut qu’elle reste claire, sinon personne n’y comprendra plus rien, ni les lecteurs, ni les contributeurs. C’est sûr qu’il vaut mieux indiquer les similitudes graphiques quand un lecteur non sinisant est susceptible de ne pas bien voir qu'il y a une différence. Mais on peut le faire ailleurs, comme on le fait pour les paronymes, et pour le même genre de raison. Lmaltier (discussion) 29 mars 2018 à 17:54 (UTC)
Ah, pardon, je n’avais pas compris l’explication : le paramètre rapprochement s’applique au modèle Étymologie graphique chinoise et non pas au modèle voir, comme je l’avais compris, et génère également le texte Voir aussi. Oui, c’est une façon de faire, mais je suis sceptique sur des modèles compliqués comme ça, il vaut bien mieux des choses simples. Le modèle voir de début de page devrait à mon avis être supprimé de la page 夂, car cet utilisation ne correspond pas à son usage normal. Lmaltier (discussion) 29 mars 2018 à 18:02 (UTC)
Euh... les mecs veulent : partagés au plus grand nombre par l’intermédiaire de Wikipédia et Wiki dictionnaire. Bon, y sont pas très doués pour le nom du projet, mais j'ai pas l'impression qu'on est au courant, nous. Ce serait bien qu'on en discute un moment avec eux, non ? --— Lyokoï (Discutons) 26 mars 2018 à 18:51 (UTC)
Il semble qu'ils veuillent ajouter des termes dans le Wiktionnaire, pas exploiter nos données en tant que telles. Il n'y a pas de problème à ce qu'ils ajoutent des définitions du moment qu'elles sont dûment sourcées (et pas inventées pour l'occasion). En outre ils n'ont pas d'obligation de nous prévenir s'ils comptent contribuer, même si on pourrait probablement les aider s'ils le faisaient. — Dakdada27 mars 2018 à 08:58 (UTC)
Je lis Les objectifs incluent de documenter, standardiser et diffuser les termes français proposés par des experts en IA, ainsi que par des terminologues., cela semble indiquer qu’ils veulent faire la promotion d’un vocabulaire inventé. Il serait effectivement bien de discuter avec eux pour en être sûrs. Lmaltier (discussion) 27 mars 2018 à 17:01 (UTC)
De la faute d'orthographe et de son expiation
Je participe assez rarement aux débats sur le wiktionnaire ; je préfère l'améliorer, ce qui m'enrichit beaucoup plus. Dans l'affaire concernant samsarâ, je me suis attaché à éviter la suppression du mot et, en vain, à le faire considérer comme une variante. Mes contradicteurs et surtout l'arbitrage m'ont déssiliés les yeux. Je me rends compte qu'il y a un sérieux problème de fond dans notre façon de bâtir le wiktionnaire. Il avait pourtant fini par être admis entre nous que nous batissions un dictionnaire descriptif et non un dictionnaire normatif, et là deux contributeurs rares ont réussis à imposer une norme. Je me rend compte, à présent, que je m suis trompé sur le niveau de l'argumentaire à mener (c'est ma part de naïveté). Il nous faut réfléchir et nous positionner sur le statut de la faute d'orthographe. Regardons par exemple cajibi, forme rare de cagibi, employé par des auteurs reconnus : est-ce une faute ? Je ne le pense pas ; la graphie est employée dès 1918, alors que le mot entre tout juste en usage dans la langue française par ceux qui sortent des tranchées. Il en est de même pour çoufisme et soufisme ; bien prétentieux serait celui qui indiquerait la graphie la plus orthodoxe et bien malin qui pourrait l'établir. Allons même plus loin, avec infractus que l'on qualifie d'erreur fort courante d'infarctus. Faute courante ! cela veut dire que l'usage en est tellement fréquent que l'on monte un appareil académique soutenu (cf l'avis de l'Académie française ) pour tenter d'en éteindre l'usage ; antienne académique que de bons puristes vont répétant, lui donnant de la faute par ci, du barbarisme par là. L'activité sur le wiktionnaire qui consiste à rechercher des exemples tirés de la littérature, dès lors que l'on embrasse le français sur une péride longue (disons depuis la fin du XVIIIe siècle avec l'irruption de la langue du peuple en révolution), nous offre un régal de foisonnement où ce qui fut faute devient règle et où la règle passe en faute (si vous n'en êtes pas convaincus, regarder l'orthographe d'avant 1835). Je propose donc que nous supprimions notre catégorie grammaticale { {erreur}} que nous sommes les seuls à avoir : il y a chez nous des verbes, des noms, de adverbes, des prépositions ... et des fautes d'orthographe. Comme l'ange et la bête pascaliens à trop vouloir faire les puristes en orthographe, nous nous gobergeons dans une fange grammaticale ; nous sommes tout simplement ridicules. Je propose donc la suppression de cette { {erreur}} comme catégorie grammaticale, de réaffecter le mot à sa vraie catégorie (nom, adjectif, verbe, etc.), et à traiter son hétérodoxie par des notes et les mentions comme { {rare}}, { {non standard}}, etc.. Les notes, pensées comme un appareil critique, permettent de développer les informations sur le mot. J'ai conscience que ma proposition va faire couiner dans le landerneau. --François GOGLINS (discussion) 31 mars 2018 à 11:38 (UTC).
Quand tu dis que nous sommes les seuls à considérer des graphies trouvées sur Internet comme des fautes, je ne peux pas être d'accord car l'erreur est humaine. On ne va tout de même pas légitimer des formes dont les propres auteurs (utilisables comme attestations ici) reconnaîtraient comme des fautes (de frappe, de retranscription orale ou d'étourderie) et les rectifieraient s'ils en avaient le pouvoir.
A mon avis nous devons être aussi intransigeants que les correcteurs d’épreuves scolaires qui doivent affronter ces erreurs au quotidien. JackPotte ($♠) 31 mars 2018 à 13:05 (UTC)
Je demande surtout la suppression de la catégorie grammaticale { {erreur}} qui n'a rien d'une catégorie grammaticale. Pour ce qui est des fautes de frappe, les coquilles, les étourderies, etc., il suffit de ne pas les inclure. Par contre, une variante, surtout si elle est employée couramment ou par un ou des auteurs reconnus, doit être traitée comme telle, quitte à conseiller d'éviter de l'utiliser dans certaines circonstances. Et ces annotations donneraient plus de vie. Dans wesh, par exemple, il y a une note qui indique que son usage est un fort marqueur social. C'est bien intéressant pour l'utilisateur. --François GOGLINS (discussion) 31 mars 2018 à 13:16 (UTC)
Tout à fait, c’est un libellé absurde, utilisé seulement pour condamner. Et par ailleurs, dans le vote d’il y a 4 ans, il y avait apparemment plutôt une majorité pour supprimer la catégorie, même si elle a été conservée. Lmaltier (discussion) 31 mars 2018 à 17:36 (UTC)
Je suis du même avis que François. Les fautes d'orthographe ne devraient figurer ni en vedette ni en modèle, et donc ni en catégorie. En revanche, elles pourraient faire l'objet d'une note, avec un texte non stigmatisant. Genre « une erreur fréquente consiste à écrire "aréoport". Ainsi quelqu'un qui entre aréoport dans le moteur de recherche tombera sur aéroport puis contenant aréoport et atterrira (oui j'assume) à nouveau sur aéroport. C'est ce que j'indiquerais si le vote était réouvert. (Et d'autres arguments si une personne venait à brandir la pancarte de non-normativité.) Joyeux long week end à vous. Delarouvraie🌿31 mars 2018 à 18:02 (UTC)
« Et donc si un jour on construisait un aéroport sur Mars ça pourrait être un aréoport. Les dyslexiques et les enfants vont adorer ! » () Cdlt, VIGNERON * discut.10 avril 2018 à 06:31 (UTC)
Mars = nouvelle ZAD ! Je comprends ton ironie. Pour ma part, je me coule dans la logique de ce dictionnaire précis, où l'on mentionne ce qui est ET ce qui n'est pas. Dans un ouvrage idéal pas davantage normatif, perso je ne mentionnerais aucune forme fautive. Delarouvraie🌿10 avril 2018 à 06:48 (UTC)
Puisque nous aimons tous la rigolade, je veux vous signaler que coude-pied était considéré par nous comme une faute d'orthographe, avec son registre { {erreur}}, alors que le mot est dans les DAF4. J'ai corrigé bien sûr... et l'article est bien plus explicatif. Un modèle à suivre pour ce que nous considérons comme des fautes ? --François GOGLINS (discussion) 1 avril 2018 à 10:41 (UTC)
Il en est de même pour donillage, qui, lui aussi n'est pas une erreur comme le wiktionnaire le prétendait, mais un mot désuet (depuis Littré qui l'assassine). Classer en { {erreur}} nous permet simplement de masquer notre paresse à ausculter les mots dans les tréfonds de leur histoire. --François GOGLINS (discussion) 1 avril 2018 à 13:22 (UTC)
Je trouve justifiable d’utiliser {{S|erreur}} si l’orthographe en question n’est pas encore assez courante. Nous ne pouvons pas juger si elle est déjà établie comme une variante ou non. Dans le cas de coude-pied, c’est bien une variante orthographique désuète plutôt qu’une faute d’orthographe, parce qu’elle est bien attestée dans plusieurs livres anciens. — TAKASUGI Shinji (d) 10 avril 2018 à 11:35 (UTC)
J’espace désormais mes « comptes rendus » car je suis certain de ne pas être le seul à effectuer ce « pensum ». Voir Utilisateur:Alphabeta/Liens WPWT créés en 2018#premier trimestre 2018 (section de la page Utilisateur:Alphabeta/Liens WPWT créés en 2018 : voir le sommaire) : j’ai supplée à 160 cas (d’absence de lien WT-WP ou WP-WT) durant le premier trimestre de 2018 contre 120 cas durant ce même trimestre de 2017 : pas dit que ce travail touche à sa fin donc.
Pour ma part cette activité avait débouché sur une autre : compléter les listes de dérivés et autres figurant dans les entrées du WT. Même si je n’ai pas effectué de comptage, j’ai effectué de nombreux rajouts. Spécialement dans Annexe:Locutions en français utilisant le verbe avoir, une annexe de l’entrée « avoir » : merci de vérifier cette annexe qui comporte peut-être des oublis.
Le rajout d’un p m’indique que c’est du moyen français. Forme savante selon le latin rescriptum (infinitif rescribere, c’est un b). Et c’est d’ailleurs ce que l’on trouve dans le Godefroy, surtout à la page 555 (le fist rescripre, 1491). Renard Migrant (discussion) 31 mars 2018 à 15:00 (UTC)
 Delarouvraie 🌿 5 mars 2018 à 09:08 (UTC)
Delarouvraie 🌿 5 mars 2018 à 09:08 (UTC) Pour Pamputt 2 mars 2018 à 06:55 (UTC)
Pour Pamputt 2 mars 2018 à 06:55 (UTC) ) 2 mars 2018 à 14:40 (UTC)
) 2 mars 2018 à 14:40 (UTC) @Noé : je viens de sortir le texte par défaut de la page d'accueil vers {{Projet de la semaine/Page par défaut}}. Merci de laisser son contenu actuel lors de l'ajout de la LexiSession. JackPotte ($♠) 10 mars 2018 à 19:55 (UTC)
@Noé : je viens de sortir le texte par défaut de la page d'accueil vers {{Projet de la semaine/Page par défaut}}. Merci de laisser son contenu actuel lors de l'ajout de la LexiSession. JackPotte ($♠) 10 mars 2018 à 19:55 (UTC)
 Noé 10 mars 2018 à 20:30 (UTC)
Noé 10 mars 2018 à 20:30 (UTC)
_en_omgeving.jpg)
 . Il me semble que seuls les navigateurs modernes sont capables de prendre en charge les images 3D. Pamputt 4 mars 2018 à 10:39 (UTC)
. Il me semble que seuls les navigateurs modernes sont capables de prendre en charge les images 3D. Pamputt 4 mars 2018 à 10:39 (UTC)
 --— Lyokoï (Discutons
--— Lyokoï (Discutons  Romainbehar (discussion) 7 mars 2018 à 18:28 (UTC)
Romainbehar (discussion) 7 mars 2018 à 18:28 (UTC)

 . --Thibaut120094 (discussion) 9 mars 2018 à 19:46 (UTC)
. --Thibaut120094 (discussion) 9 mars 2018 à 19:46 (UTC)


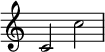
 . — Dakdada 20 mars 2018 à 22:46 (UTC)
. — Dakdada 20 mars 2018 à 22:46 (UTC)

 J'aime. Otourly (discussion) 23 mars 2018 à 13:50 (UTC)
J'aime. Otourly (discussion) 23 mars 2018 à 13:50 (UTC)_-_Saint_John_the_Baptist_-_Google_Art_Project.jpg)

.jpg)





.svg){kind=link}
{kind=link}